参数微调
August 17, 2025About 2 min
参数微调
下游任务适配
预训练模型难以直接适配到下游任务。
预训练模型:倾向于续写或复读一句话
通过上下文学习,可以在一定程度上适配到下游任务。
上下文学习:能够模仿示例内容完成任务
上下文学习的不足
尽管上下文学习能有效利用大模型的能力,但其性能和效率方面仍存在一些局限性
指令微调
为了保证下游任务性能,语言模型需要定制化调整以完成下游任务适配。
指令数据
指令数据通常包含指令(任务描述)、示例(可选)、问题和回答。通常构造指令数据集有两种方式:(1)数据集成;(2)大语言模型生成。
监督微调(SFT)
基于构造的指令数据集,对大模型进行监督微调(Supervised Fine-Tuning)。对于现有大语言模型,通常以自回归方式进行训练。
Teacher forcing
全量监督微调的挑战 FFT
然而,由于全量监督微调需要更新所有模型参数,当面对拥有庞大参数量的大模型时,全量监督微调会消耗大量存储和计算资源。
- GPU内存不足
- 全量微调效率低
参数高效微调 PEFT
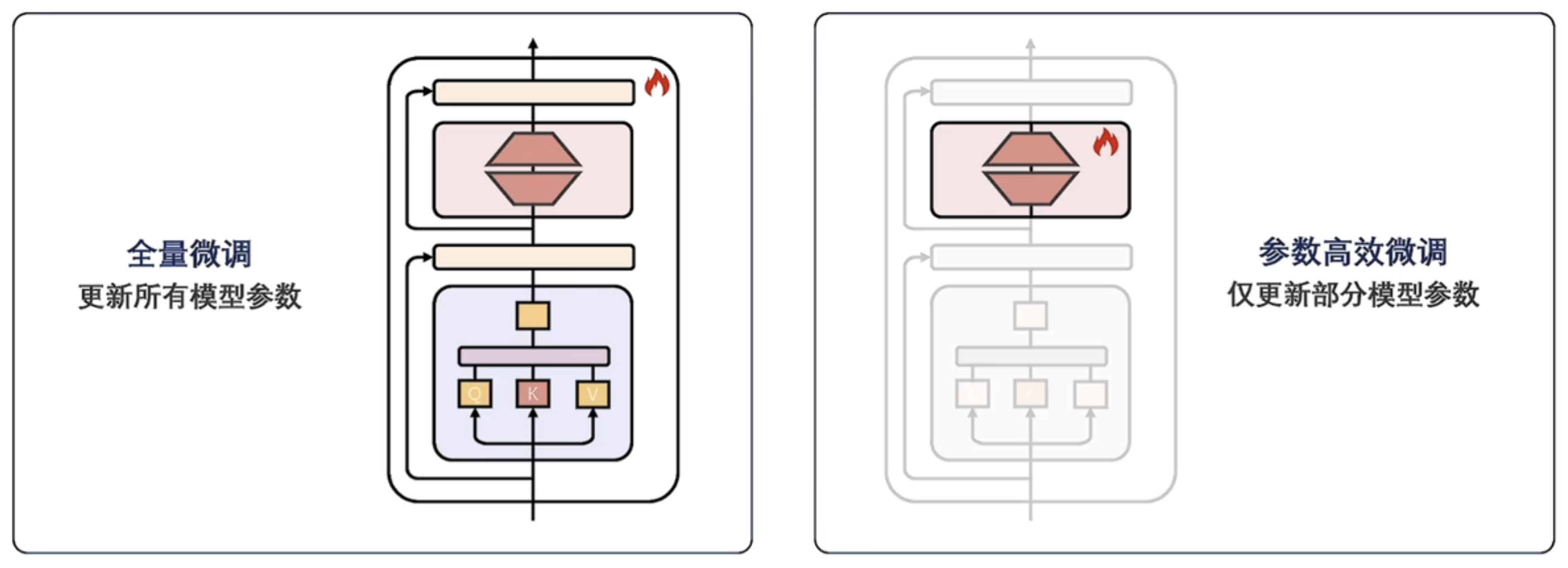
为了解决全量微调的问题,参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)避免更新全部参数,在保证微调性能的同时,减少更新的参数数量和计算开销。
参数高效微调的优势
PEFT技术主要有三个方面的优势:
计算效率:全量微调和参数高效微调显存占用对比。其中,PEFT方法减少了需要更新的参数数量,显著减少了训练时的计算资源。
存储效率:PEFT方法仅需要保留部分微调参数,显著降低了微调模型的存储空间,尤其适用于存储受限的设备。
eg. LoRA rank=32, <100MB
适应性强:参数高效微调技术在降低微调成本的同时,保证微调性能不受影响。且使模型可以快速适应不同任务,具有很好的灵活性。
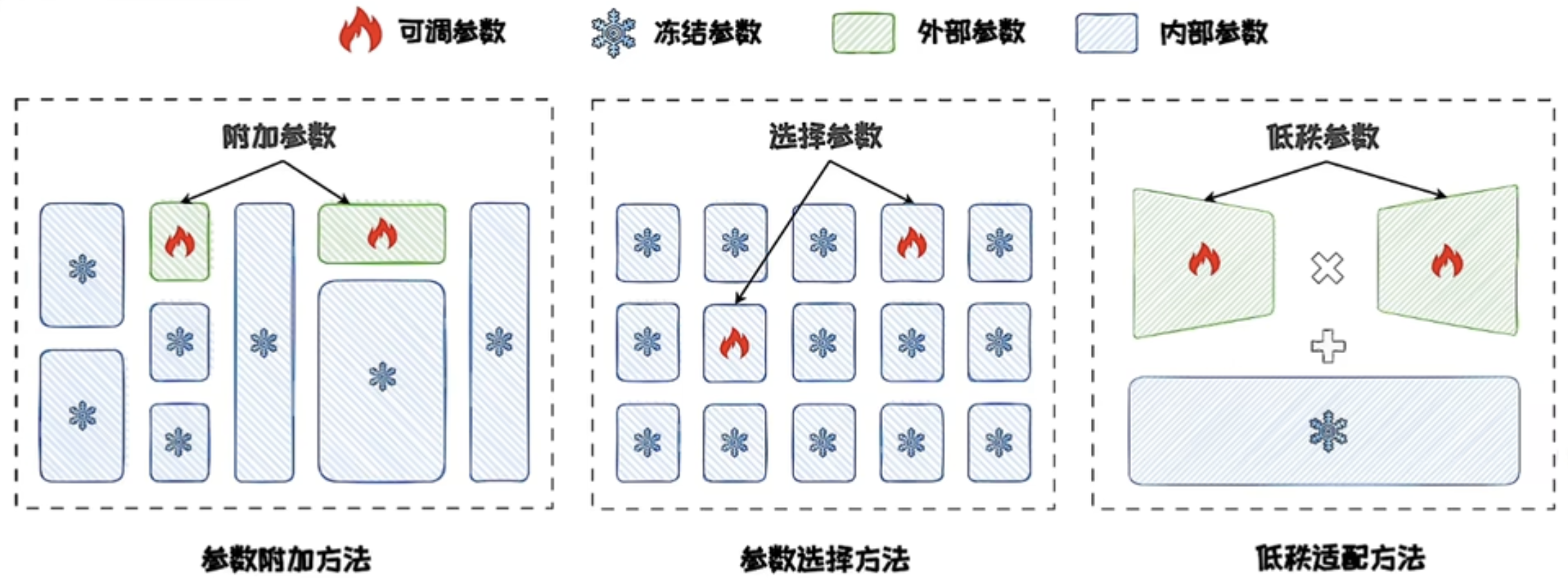
主流PEFT方法可分为三类:
- 参数附加方法
- 参数选择方法
- 低秩适配方法