vLLM
August 17, 2025Less than 1 minute
vLLM
KV Cache
在大模型推理时,按照可生成最长序列长度分配显存。
造成三种类型的浪费:
- 预分配,但不会用到。
- 预分配,但尚未用到。
- 显存之间的间隔碎片,不足以预分配给下一个文本生成。
利用率只有20%-40%
vllm就是处理碎片问题
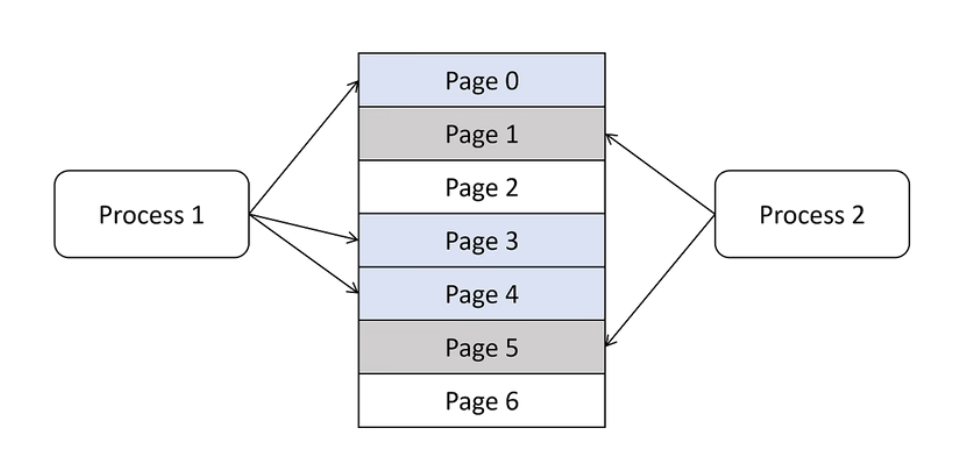
Page Attention
虚拟内存和页管理技术
KV Cache
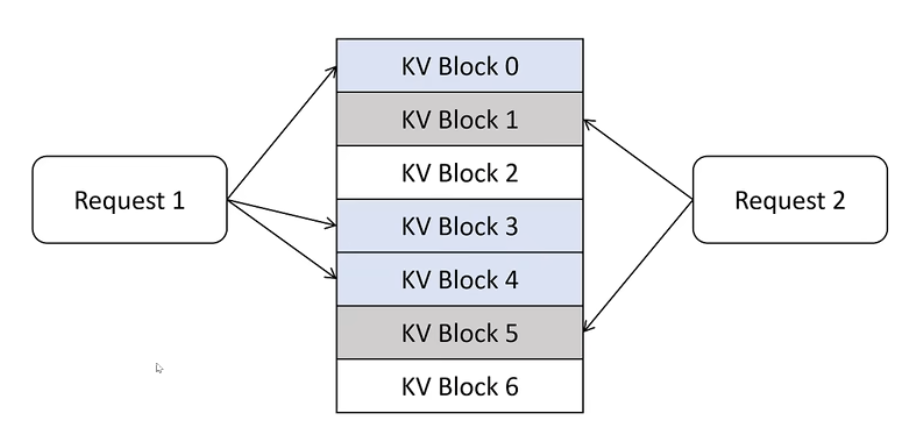
KV Block是4个token,最多浪费3个token,所以解决预分配问题
虚拟内存
逻辑KV Cache和物理内存的映射表
逻辑上连续,实际物理上不连续
- 按需分配,不提前预分配。
- 按B引ock分配,减少碎片大小。
- 虚拟内存,方便实现调用。
=> 利用率从20-40%到96%
Sharing KV Blocks
用大语言模型同一个Prompt,希望生成多个Output时。
Prompt:
请把下边这句话翻译为英文:
引用计数