聚类召回
August 31, 2025About 2 min
聚类召回
基本思想
- 如果用户喜欢一篇笔记,那么他会喜欢内容相似的笔记。
- 事先训练一个神经网络,基于笔记的类目和图文内容,把笔记映射到向量。
- 对笔记向量做聚类,划分为1000 cluster,记录每个 cluster的中心方向。(k-means聚类,用余弦相似度。)
线上召回
- 给定用户ID,找到他的last-n交互的笔记列表,把这些笔记作为种子笔记。
- 把每篇种子笔记映射到向量,寻找最相似的cluster (知道了用户对哪些cluster感兴趣)
- 从每个cluster的笔记列表中,取回最新的m篇笔记。
- 最多取回mn篇新笔记。
内容相似度模型
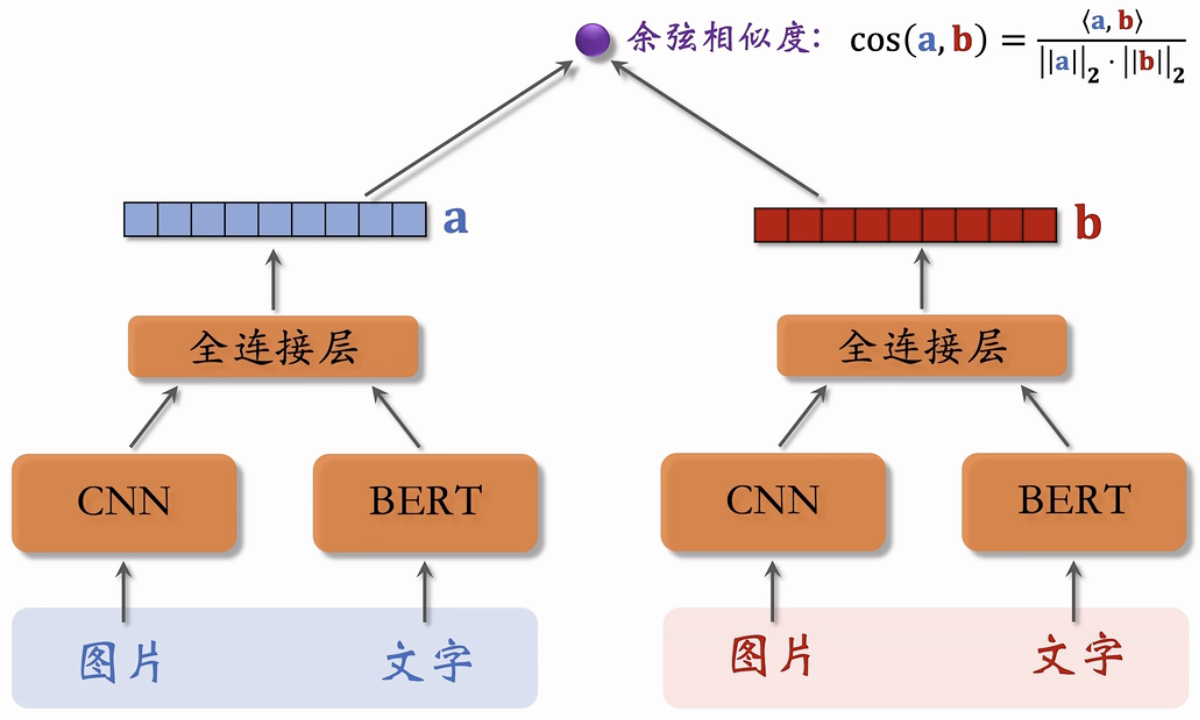
模型的训练
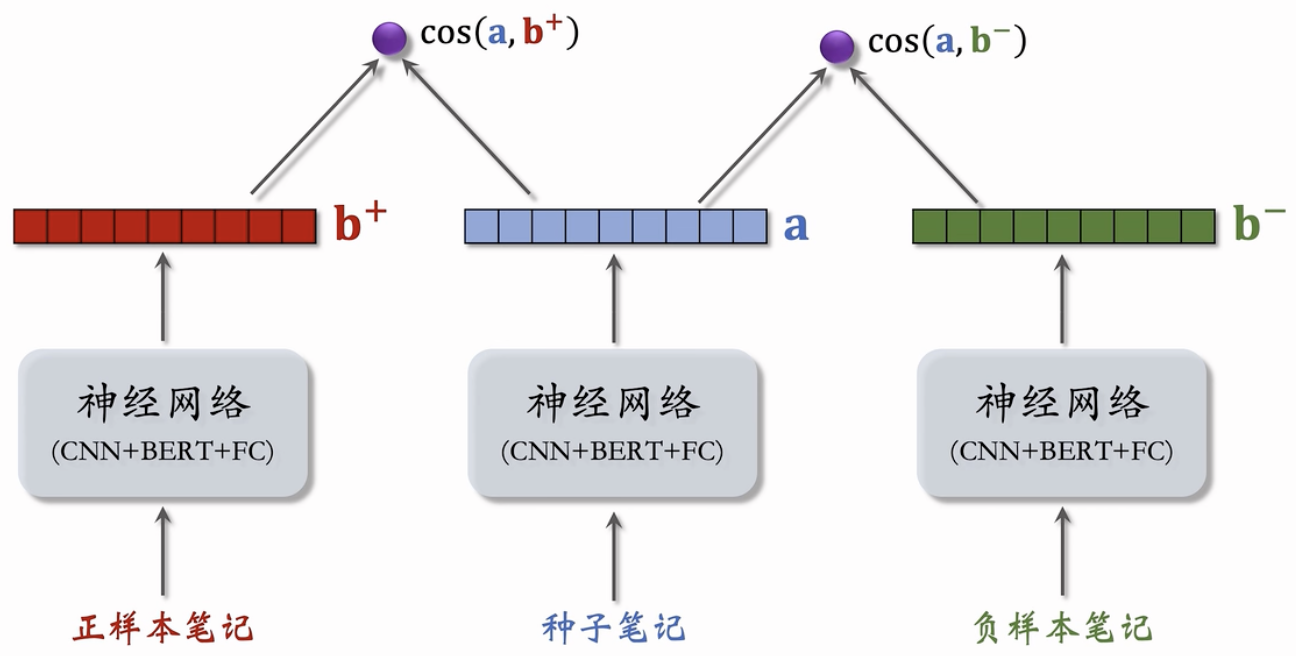
基本想法:鼓励cos(a,b+)大于cos(a,b-)
- Triplet hinge loss:
- L(a,bt,b)=max{0,cos(a,b)+m-cos(a,b+)3.
- Triplet logistic loss:
- L(a,bf,b)=log(1+exp(cos(a,b)-cos(a,b+))).
正样本
- 方法一:人工标注二元组的相似度
- 方法二:算法自动选正样本
- 筛选条件:
- ·只用高曝光笔记作为二元组(因为有充足的用户交互信息)
- ·两篇笔记有相同的二级类目,比如都是“菜谱教程”。
- 用ItemCF的物品相似度选正样本。
- 筛选条件:
负样本
- 从全体笔记中随机选出满足条件的:
- 字数较多(神经网络提取的文本信息有效)
- ·笔记质量高,避免图文无关。
总结:
- 基本思想:根据用户的点赞、收藏、转发记录,推荐内容相似的笔记。
- 线下训练:多模态神经网络把图文内容映射到向量。
- 线上服务:用户喜欢的笔记→特征向量最近的Cluster→新笔记