SIM
August 31, 2025About 2 min
SIM
用户长期兴趣
- 注意力层的计算量∝(用户行为序列的长度)
- 只能记录最近几百个物品’否则计算量太大。
- 缺点:关注短期兴趣,遗忘长期兴趣·
目标:保留用户长期行为序列(很大),而且计算量不会过大。
改进DIN:
·DIN对LastN向量做加权平均’权重是相似度
·如果某La$tN物品与候选物品差异很大,则权重接近零。
·快速排除掉与候选物品无关的LαstN物品,降低注意力层的计算量。
Qi et al.Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction.In CIKM,2020.
保留用户长期行为记录,的大小可以是几千。
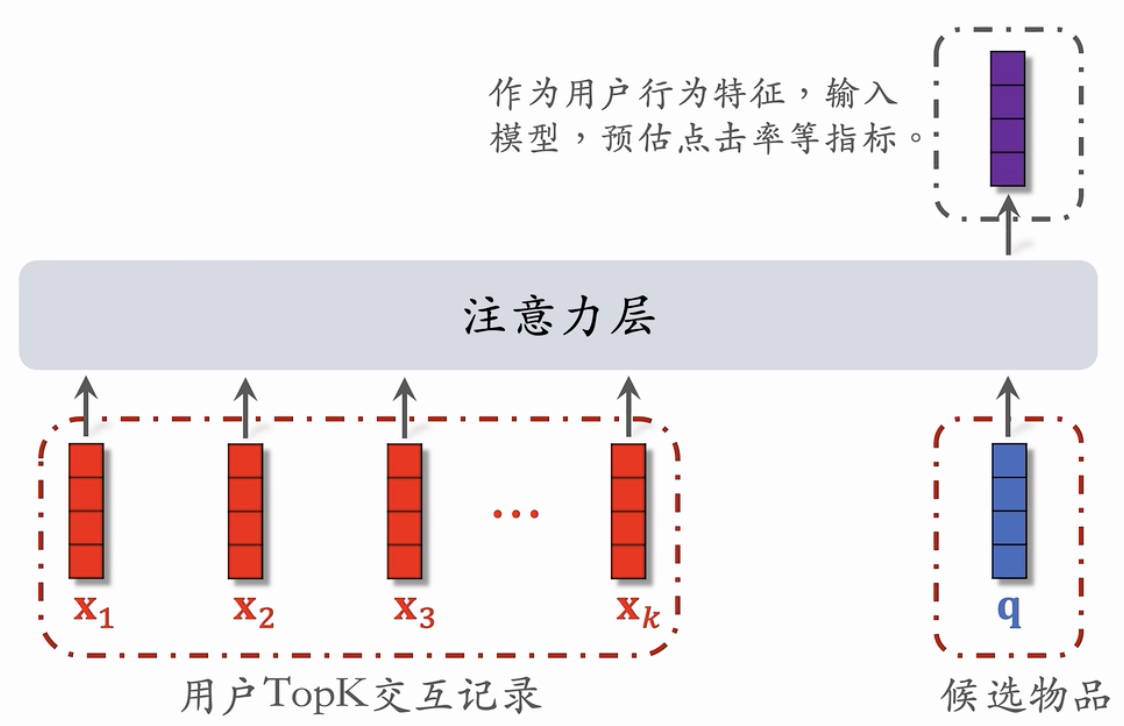
对于每个候选物品,在用户Lα$tN记录中做快速查找,找到k个相似物品。
把LastN变成TopK,然后输入到注意力层·
SIM模型减小计算量(从n降到k)
第一步:查找
- 方法一:Iard Search
- ·根据候选物品的类目,保留Lα$tN物品中类目相同的。
- ·简单’快速’无需训练。
- 方法二:Soft Search
- ·把物品做embedding,变成向量。
- ·把候选物品向量作为query,做k近邻查找’保留LastN 物品中最接近的飞个。
- ·效果更好’编程实现更复杂。
第二部:注意力机制
使用时间信息
用户与某个LαstN物品的交互时刻距今为δ。
对δ做离散化,再做embedding,变成向量d。
1d, 7d, 30d, 1y, 1+y
把两个向量做concatenation,表征一个LastN物品。
- 向量x是物品的embedding。
- 向量d是时间的embedding。
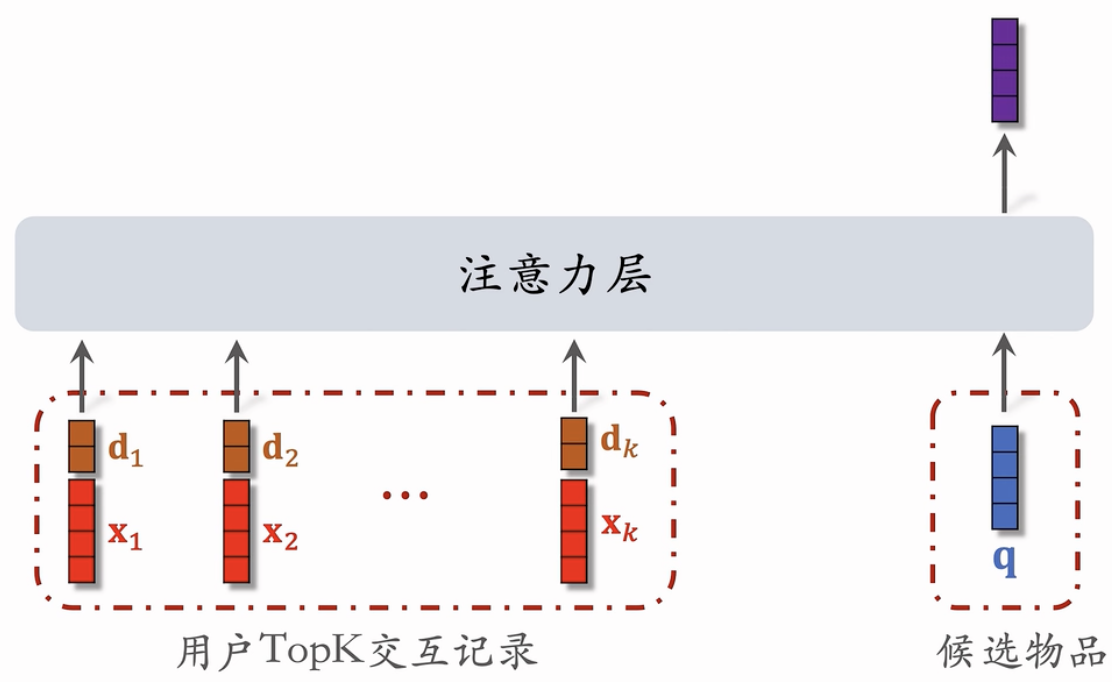
为什么SIM使用时间信息?
- DIN的序列短,记录用户近期行为。
- SIM的序列长’记录用户长期行为。
- 时间越久远,重要性越低。
结论
- 长序列(长期兴趣)优于短序列(近期兴趣)。
- 注意力机制优于简单平均。
- Soft search还是hard search?取决于工程基建。
- 使用时间信息有提升。