Two tower
August 31, 2025About 3 min
Two tower
Deep Structured Semantic Models
双塔模型
模型
用户塔
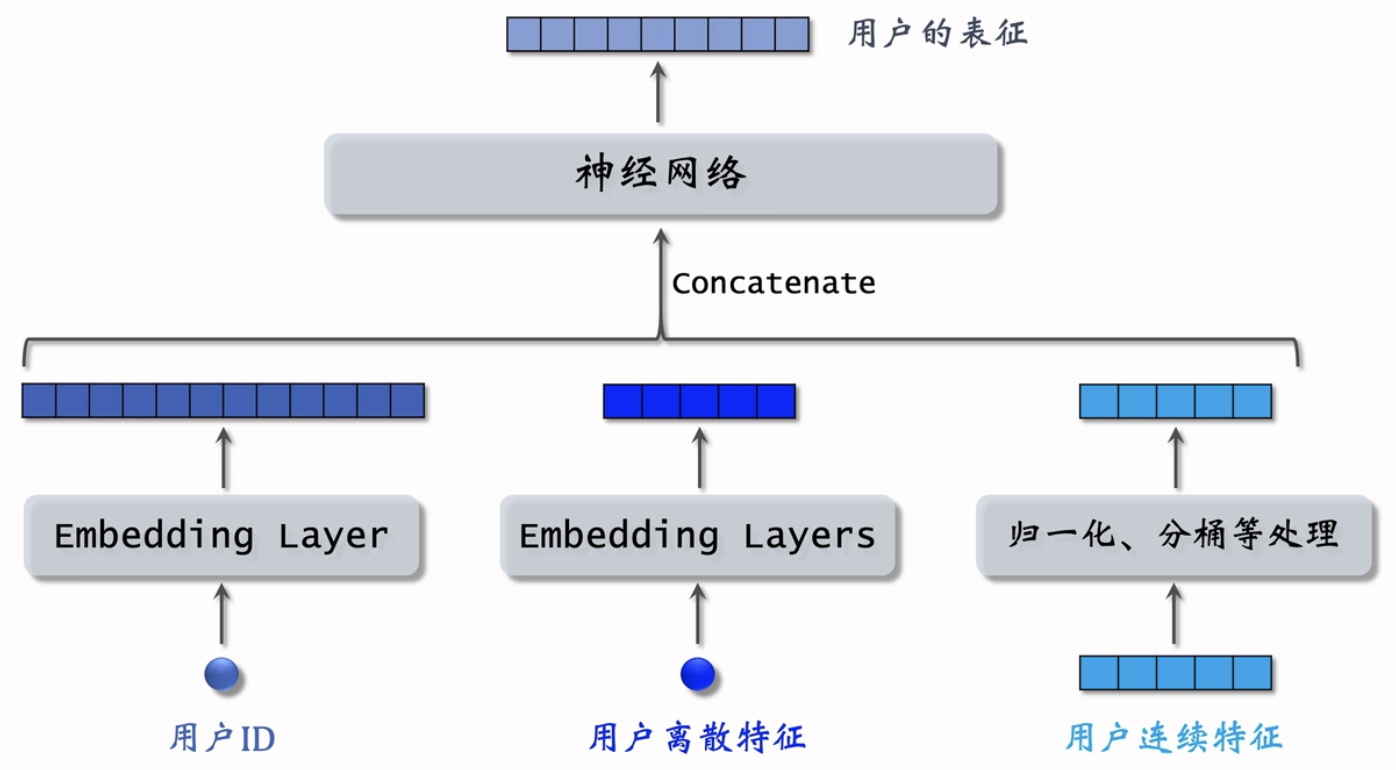
物品塔
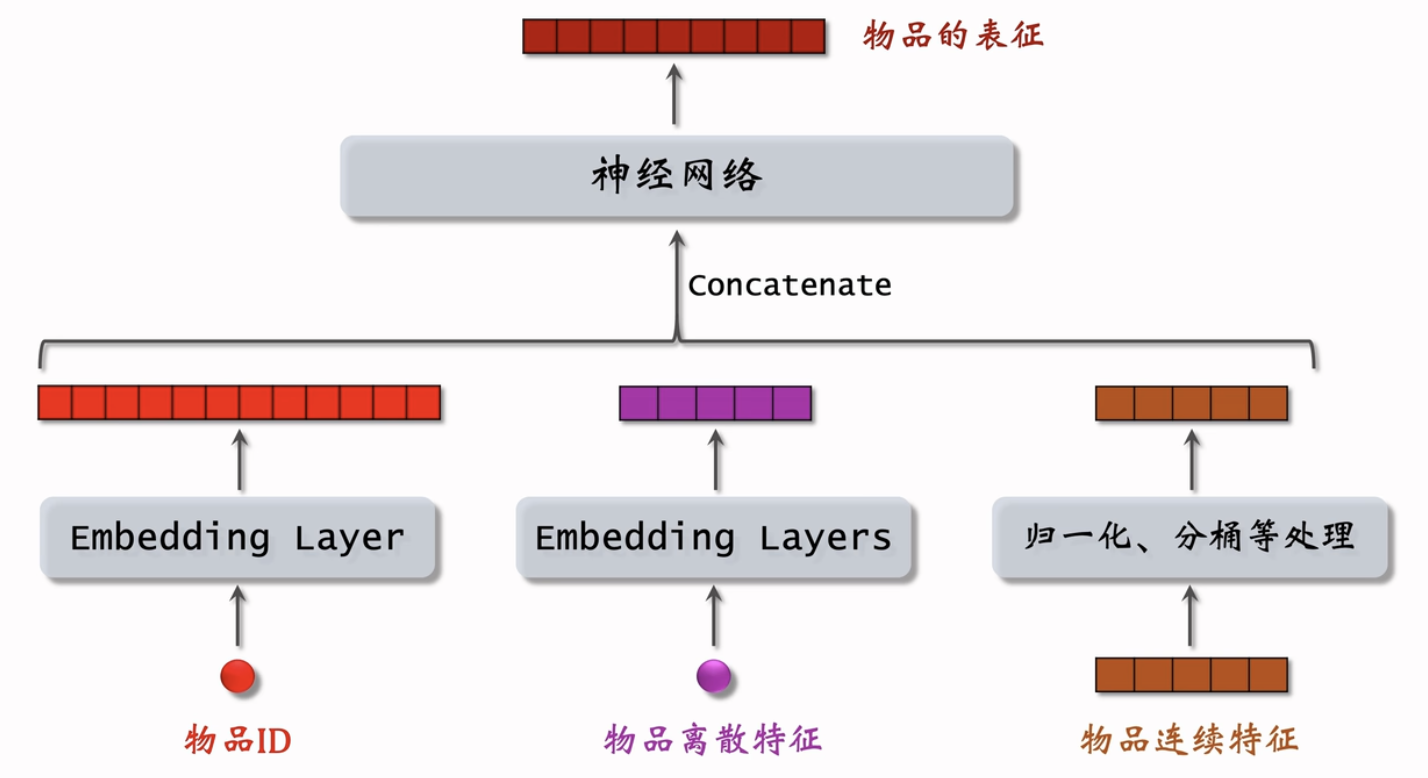
后期融合
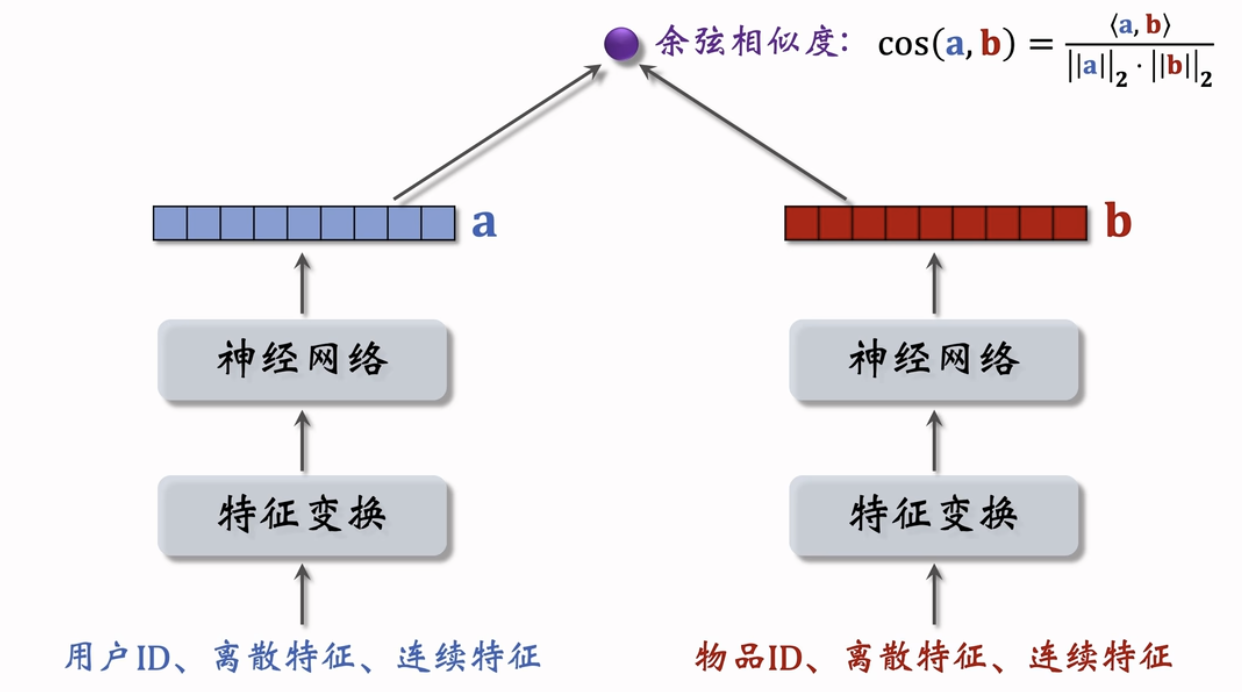
训练
参考文献:
- Jui-Ting Huang et al.Embedding-based Retrieval in Facebook Search.In KDD,2020.
- Xinyang Yi et al.Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations.In RecSys,2019.
- Pointwise:独立看待每个正样本、负样本,做简单的二元分类
- Pairwise:每次取一个正样本、一个负样本[1]。
- Listwise:每次取一个正样本、多个负样本[2]。
样本选择
- 正样本:用户点击的物品。
- 负样本[1,2]:
- 没有被召回的?
- 召回但是被粗排、精排淘汰的?
- 曝光但是未点击的?
Pointwise 训练
- 把召回看做二元分类任务
- 对于正样本,鼓励cos(a,b)接近+1。
- 对于负样本,鼓励cos(a,b)接近一1。
- 控制正负样本数量为1:2或者1:3。
Pairwise 训练
- 一个batch内有n对正样本。
- 组成n个list,每个list中有1对正样本和n-1对负样本。
基本想法:鼓励cos(a,b+)大于cos(a,b-)
- 如果cos(a,b+)大于cos(a,b-)+m,则没有损失。
- 否则,损失等于cos(a,b-)+m-cos(a,b+)。
m是超参数,要调,比如设置成1
Loss
Triplet hinge loss:
Triplet logistic loss:
: 大于0的超参数,控制损失函数形状,需要手动调
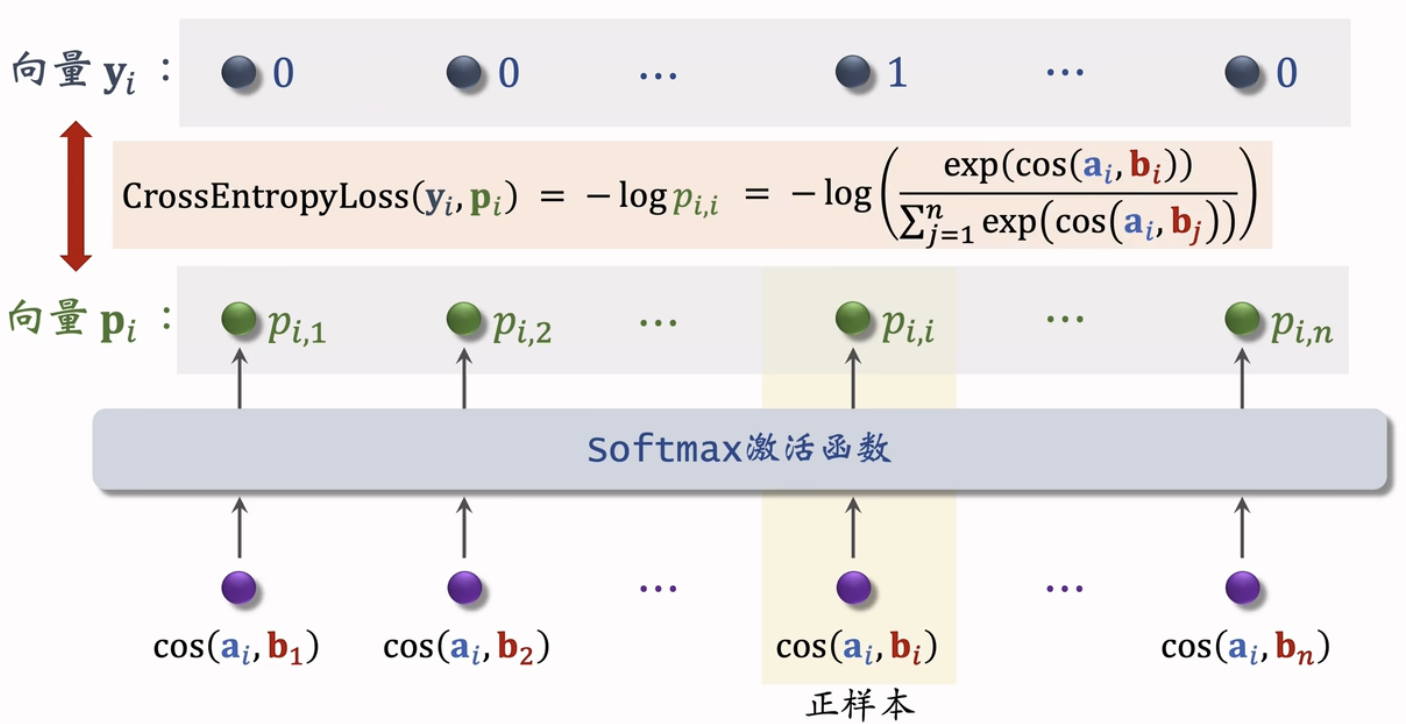
Listwise 训练
- 一条数据包含:
- 一个用户,特征向量记作。
- 一个正样本,特征向量记作。
- 多个负样本,特征向量记作。
- 鼓励$$\cos(a,b^+)$$尽量大。
- 鼓励尽量小。
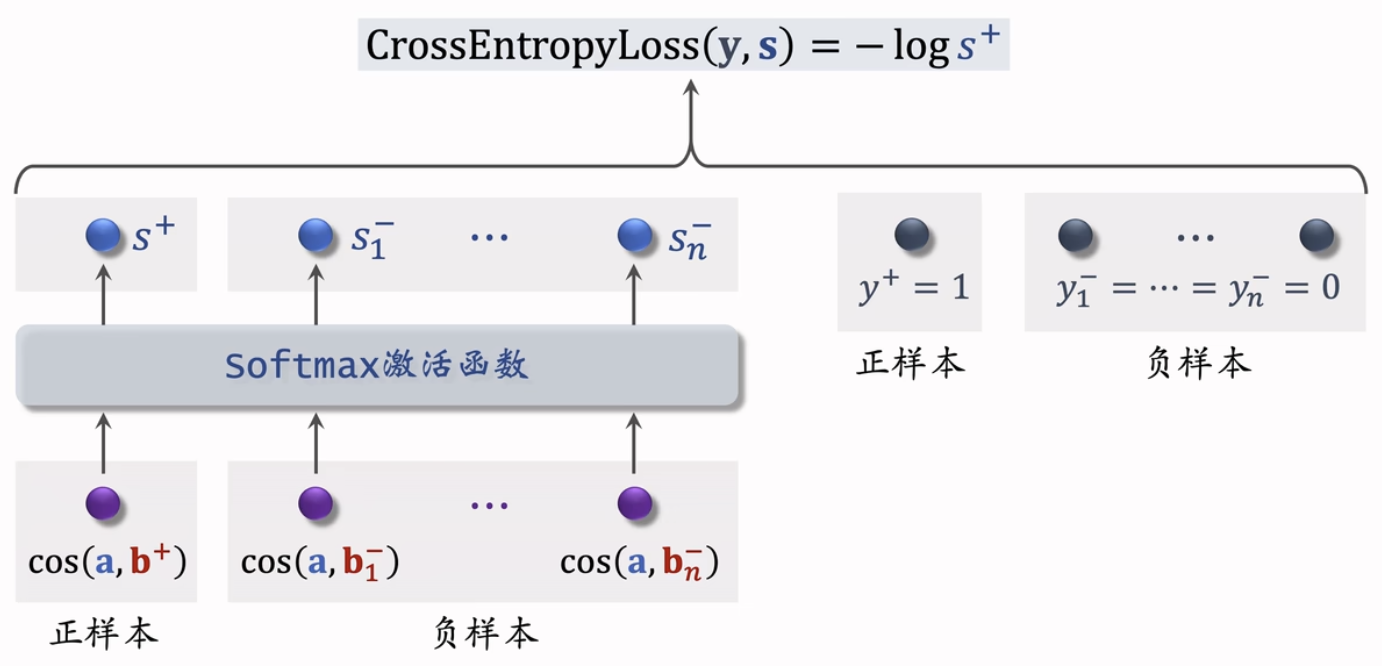
损失函数
引入纠偏
- 从点击数据中随机抽取n个用户一物品二元组,组成一个batch。
- 双塔模型的损失函数:
- 做梯度下降,减小损失函数:
总结
双塔模型
- 用户塔、物品塔各输出一个向量,两个向量的余弦
- 相似度作为兴趣的预估值。
- 三种训练的方式:pointwise、pairwise、listwise。
- 正样本:用户点击过的物品。
- 负样本:全体物品(简单)、被排序淘汰的物品(困难)
召回
- 做完训练,把物品向量存储到向量数据库,供线上最近邻查找
- 线上召回时,给定用户D、用户画像’调用用户塔现算用户向量a。
- 把a作为query,查询向量数据库,找到余弦相似度最高的k个物品向量,返回k个物品D。
更新模型
- 全量更新:今天凌晨,用昨天的数据训练整个神经网络,做1 epoch的随机梯度下降。
- 增量更新:用实时数据训练神经网络,只更新ID Embedding,锁住全连接层。
- 实际的系统:
- 全量更新&增量更新相结合。
- 每隔几十分钟,发布最新的用户ID Embedding,供用户塔在线上计算用户向量