线上服务
August 31, 2025About 2 min
线上服务
线上召回
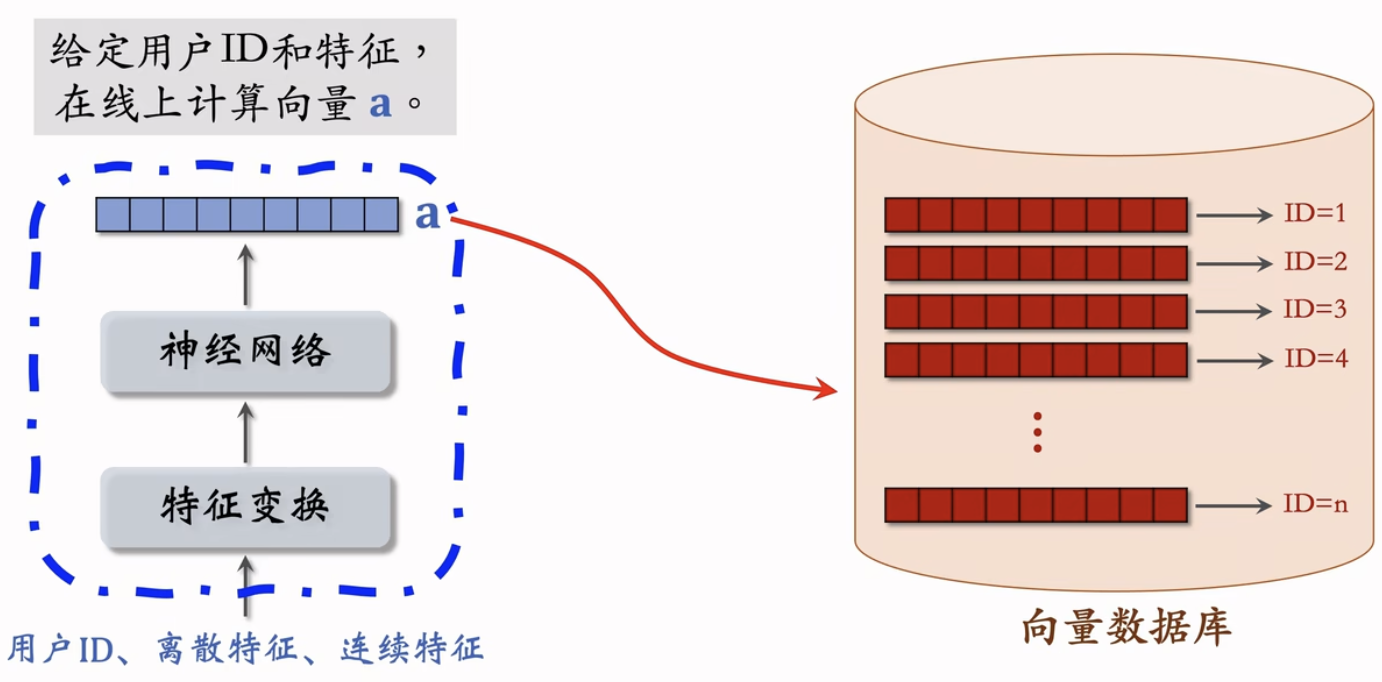
离线存储:把物品向量b存入向量数据库
- 完成训练之后,用物品塔计算每个物品的特征向量b
- 把几亿个物品向量b存入向量数据库(比如Milvus、Faiss、HnswLib)
- 向量数据库建索引,以便加速最近邻查找。
线上召回:查找用户最感兴趣的k个物品
- 给定用户ID和画像,线上用神经网络算用户向量a。
- 最近邻查找:
- 把向量a作为query,调用向量数据库做最近邻查找。
- 返回余弦相似度最大的k个物品,作为召回结果。
why:事先存储物品向量b,线上现算用户向量a
- 每做一次召回,用到一个用户向量a,几亿物品向量b。(线上算物品向量的代价过大)
- 用户兴趣动态变化,而物品特征相对稳定。(可以离线存储用户向量,但不利于推荐效果)
模型更新
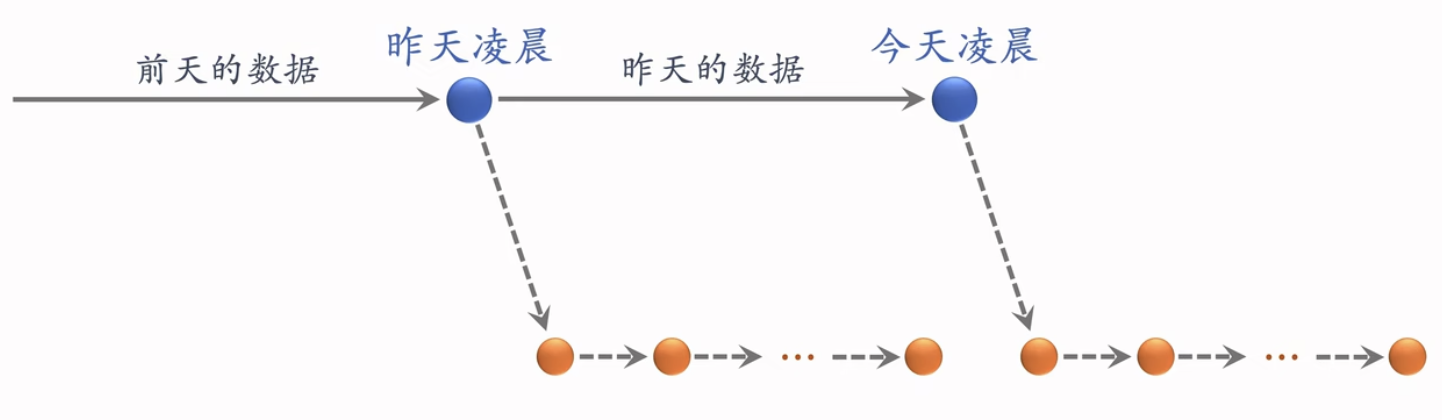
全量更新:今天凌晨,用昨天全天的数据训练模型。
- 在昨天模型参数的基础上做训练。(不是随机初始化)》
- 用昨天的数据,训练1 epoch,即每天数据只用一遍。
- 发布新的用户塔神经网络和物品向量,供线上召回使用
- 全量更新对数据流、系统的要求比较低。
增量更新:做online learning更新模型参数。
- 用户兴趣会随时发生变化。
- 实时收集线上数据,做流式处理,生成TFRecord文件。
- 对模型做online learning,增量更新ID Embedding参数。(不更新神经网络其他部分的参数。)
- 发布用户ID Embedding,供用户塔在线上计算用户向量
问题:能否只做增量更新,不做全量更新?
- 小时级数据有偏;分钟级数据偏差更大。
- 全量更新:random shuffle一天的数据,做1 epoch训练。
- 增量更新:按照数据从早到晚的顺序,做1 epoch训练。
- 随机打乱优于按顺序排列数据,全量训练优于增量训练。