Matrix Completion 矩阵补充
12/15/25About 2 min
Matrix Completion 矩阵补充
最简单的一种方法,实际效果不好
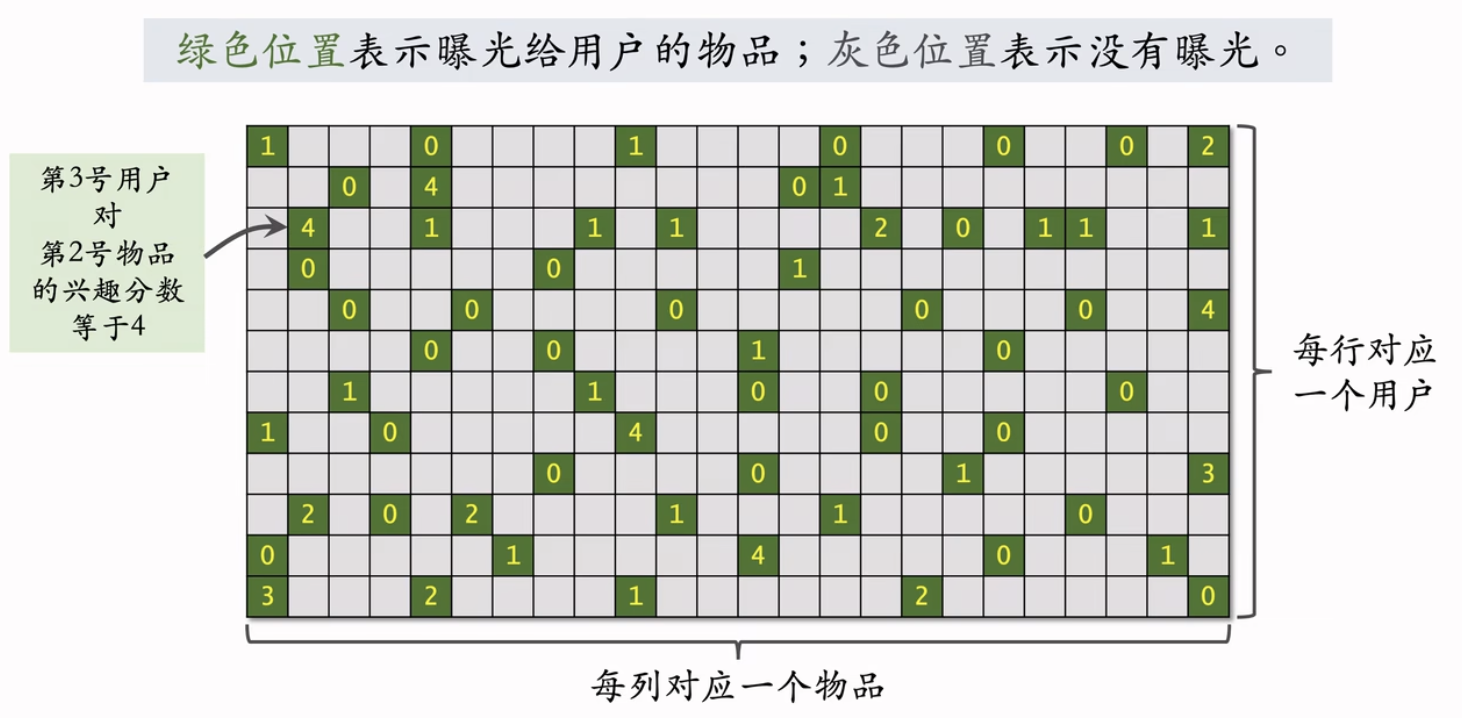
数据集
- 数据集:(用户 D,物品 D,兴趣分数) 的集合,记作。
- 数据集中的兴趣分数是系统记录的,比如:
- ·曝光但是没有点击 →0 分
- ·点击、,点赞、收藏、转发 → 各算 1 分
- ·分数最低是 0,最高是 4。
训练
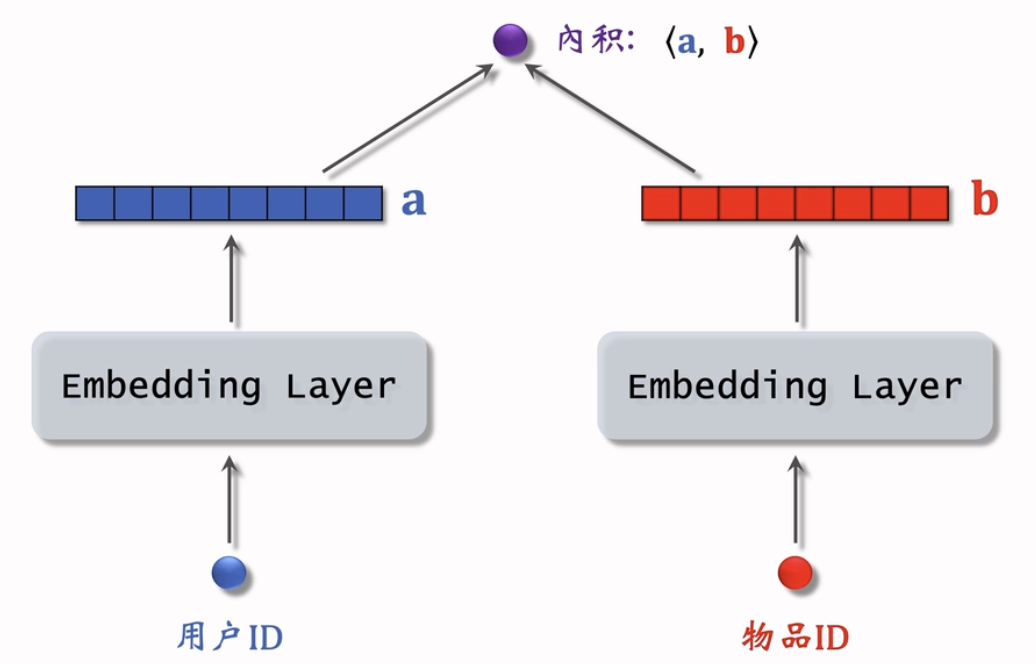
- 把用户 ID、物品 ID 映射成向量
- ·第 u 号用户 → 向量
- ·第 i 号物品 → 向量
- 求解优化问题,得到参数 A 和 B。
缺点
在实践中效果不好…
缺点 1:仅用 ID embedding,没利用物品、用户属性。
- ·物品属性:类目、关键词、地理位置、作者信息。
- ·用户属性:性别、年龄、地理定位、感兴趣的类目。
- ·双塔模型可以看做矩阵补充的升级版。
缺点 2:负样本的选取方式不对。
- ·样本:用户一物品的二元组,记作(u,i)。
- ·正样本:曝光之后,有,点击、交互。(正确的做法)
- ·负样本:曝光之后,没有点击、交互。(错误的做法)
缺点 3:做训练的方法不好。
- 內积不如余弦相似度。
- 用平方损失(回归),不如用交叉熵损失(分类)。
模型存储
- 训练得到矩阵 A 和 B。
- ·A 的每一列对应一个用户。
- ·B 的每一列对应一个物品。
- 把矩阵 A 的列存储到 key-value 表。
- ·key 是用户 ID,value 是 A 的一列。
- ·给定用户 ID,返回一个向量(用户的 embedding)o
- 矩阵 B 的存储和索引比较复杂。
线上服务
把用户 ID 作为 key,查询 key-value 表’得到该用户的向量,记作 a。
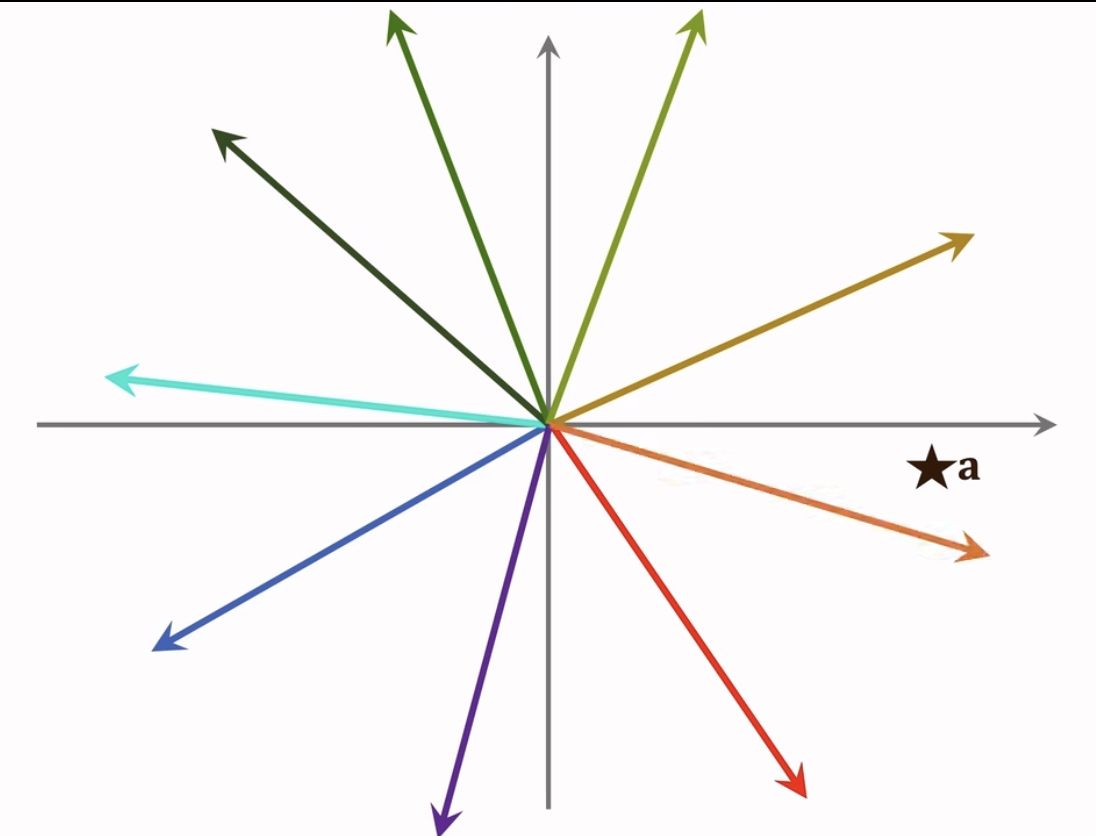
最近邻查找:查找用户最有可能感兴趣的 k 个物品,作为召回结果。
- ·第 i 号物品的 embedding 向量记作 bio
- ·內积(a,b〉是用户对第 i 号物品兴趣的预估。
- ·返回內积最大的 k 个物品。
如果枚举所有物品,时间复杂度正比于物品数量
近似最近邻查找(Approximate Nearest Neighbor Search)
支持最近邻查找的系统
- ·系统:Milvus、Faiss、HnswLib、等等。
- ·衡量最近邻的标准:
- ·欧式距离最小(L2 距离)
- ·向量內积最大(內积相似度)
- ·向量夹角余弦最大(cosine 相似度)
- 针对不支持 cosine 的系统,只需要把向量做归一化,然后内积就等于 cosine 了
- 把物品 ID、用户 ID 做 embedding,映射成向量。
- 两个向量的內积作为用户 u 对物品 i 兴趣的预估。
- 让拟合真实观测的兴趣分数,学习模型的 embedding 层参数。
- 矩阵补充模型有很多缺点,效果不好。