基本类型
基本类型
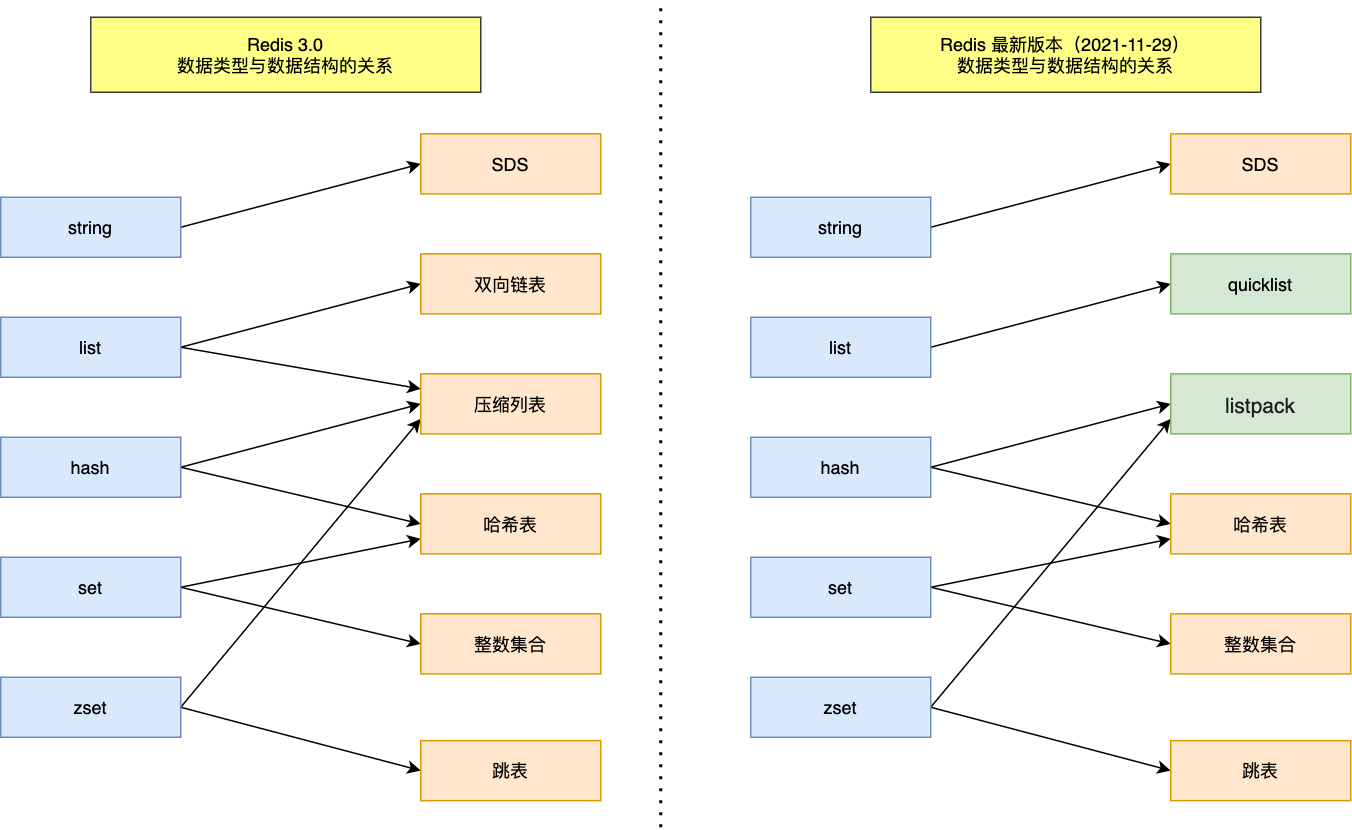
基本类型与底层数据结构对应关系如下图所示:
String
String 是最基本的 key-value 结构,key 是唯一标识,value 是具体的值,value 其实不仅是字符串, 也可以是数字(整数或浮点数),value 最多可以容纳的数据长度是 512M。
原理
String 类型的底层的数据结构实现主要是 int 和 SDS(简单动态字符串)。
SDS 和我们认识的 C 字符串不太一样,SDS 相比于 C 的原生字符串:
- SDS 不仅可以保存文本数据,还可以保存二进制数据。因为
SDS使用len属性的值而不是空字符来判断字符串是否结束,并且 SDS 的所有 API 都会以处理二进制的方式来处理 SDS 存放在buf[]数组里的数据。所以 SDS 不光能存放文本数据,而且能保存图片、音频、视频、压缩文件这样的二进制数据。 - SDS 获取字符串长度的时间复杂度是 O(1)。因为 C 语言的字符串并不记录自身长度,所以获取长度的复杂度为 O(n);而 SDS 结构里用
len属性记录了字符串长度,所以复杂度为O(1)。 - Redis 的 SDS API 是安全的,拼接字符串不会造成缓冲区溢出。因为 SDS 在拼接字符串之前会检查 SDS 空间是否满足要求,如果空间不够会自动扩容,所以不会导致缓冲区溢出的问题。
字符串对象的内部编码(encoding)有 3 种 :int、raw 和 embstr。
场景
缓存对象
使用 String 来缓存对象有两种方式:
- 直接缓存整个对象的 JSON,命令例子:
SET user:1 '{"name":"xiaolin", "age":18}'。 - 采用将 key 进行分离为 user:ID:属性,采用 MSET 存储,用 MGET 获取各属性值,命令例子:
MSET user:1:name xiaolin user:1:age 18 user:2:name xiaomei user:2:age 20。
常规计数
因为 Redis 处理命令是单线程,所以执行命令的过程是原子的。因此 String 数据类型适合计数场景,比如计算访问次数、点赞、转发、库存数量等等。
分布式锁
setnx是不可重入
也可以做可重入,但是需要多种机制保证
List
原理
List 对象的底层数据结构:
Redis 3.0,list + ziplist
小规模时 ziplist,大规模时 list
ziplist
优点是内存紧凑,访问效率高
缺点是更新效率低,并且数据量较大时,可能导致大量的内存复制
list
优点是节点修改的效率高
缺点需要额外内存开销,并且节点较多时,会产生大量的内存碎片
Redis 3.2,quicklist (+ ziplist)
Redis 7.0,quicklist (+ listpack)
场景
消息队列
消息队列在存取消息时,必须要满足三个需求,分别是消息保序、处理重复的消息和保证消息可靠性。
Hash
原理
Hash 类型的底层数据结构是由listpack 或哈希表实现的:
- 元素个数小于
512个(默认值,可由hash-max-ziplist-entries配置),所有值小于64字节(默认值,可由hash-max-ziplist-value配置)的话,使用ListPack作为 Hash 类型的底层数据结构; - 不满足上面条件,使用哈希表作为 Hash 类型底层数据结构。
场景
一般对象用 String + Json 存储,对象中某些频繁变化的属性可以考虑抽出来用 Hash 类型存储。
购物车
经常修改其中部分内容
分布式锁
Redisson 的实现就是 hash,一个记录线程 id,一个记录重入次数
Set
原理
Set 类型的底层数据结构是由整数集合或哈希表实现的:
- 元素都是整数且元素个数小于
512(默认值,set-maxintset-entries配置)个,会使用整数集合作为 Set 类型的底层数据结构; - 不满足上面条件,则使用哈希表作为 Set 类型的底层数据结构。
场景
点赞
共同关注
SINTER, SDIFF
抽奖活动
SRANDMEMBER, SPOP
Zset / Sorted Set
原理
Zset 类型的底层数据结构是由listpack 或跳表实现的:
- 元素个数小于
128个,并且每个元素的值小于64字节时,Redis 会使用listpack作为 Zset 类型的底层数据结构; - 不满足上面的条件,Redis 会使用skiplist作为 Zset 类型的底层数据结构;