Bloom Filter
Bloom Filter
- 标准布隆过滤器 Standard Bloom Filter
- 计数布隆过滤器 Counting Bloom Filter
如果我们想要进一步节省空间,并且容许较小的误差的话,还可以使用布隆过滤器(B 引 oom Filter)进一步优化。布隆过滤器就是基于 Bitmap 实现的,只是多加了哈希函数映射这一步。
Bloom Filter 是一个叫做 Bloom 的老哥于 1970 年提出的。我们可以把它看作由 Bitmap 和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于传统的 Bitmap,Bloom Filter 占用的空间更少,但其结果不一定是完全准确的。bloomfilter 说不存在则一定不存在,说存在时不一定存在。
Bloom Filter 的常见应用场景如下:
- 判断给定数据是否存在:比如判断一个数字是否存在于包含大量数字的数字集中(数字集很大,上亿)、防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤(判断一个邮件地址是否在垃圾邮件列表中)、黑名单功能(判断一个 P 地址或手机号码是否在黑名单中)等等。
- 去重:如果需要对一个大的数据集进行去重操作,可以使用 Bloom Filter 来记录每个元素是否出现过。比如爬给定网址的时候对已经爬取过的 URL 去重、对巨量的 QQ 号/订单号去重。
Bloom Filter 和 Bitmap 的应用场景类似,都是为了解决海量数据的存在性问题。
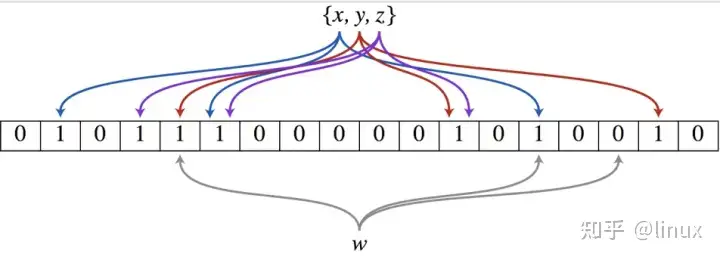
当一个元素加入布隆过滤器中的时候,会进行如下操作:
- 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。
当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:
- 对给定元素再次进行相同的哈希计算;
- 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
Redis 也支持 Bloom Filter,不过,我们需要先安装一下。
docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest
原理
布隆过滤器内部维护一个 bitArray(位数组), 开始所有数据全部置 0 。当一个元素过来时,能过多个哈希函数(hash1,hash2,hash3…)计算不同的在哈希值,并通过哈希值找到对应的 bitArray 下标处,将里面的值 0 置为 1 。
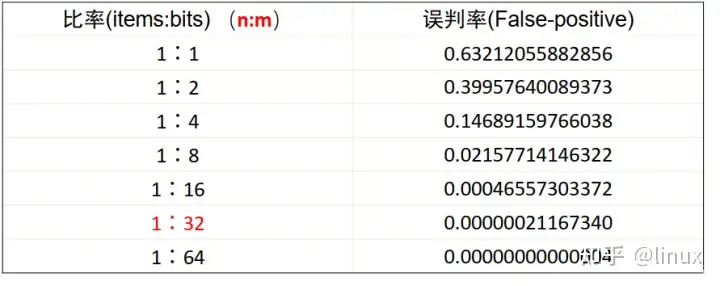
误报率(False positive),又叫假阳性。这个意思抽象出来,就是把本来不存在的事物(False)误报为已存在事物(Positive)的错误率。在一般的应用场景中,有极小的误报率是可以被接受的。比如爬虫时,少爬几个网页并没有什么太大关系;医疗检查时,一个健康的人被医生误判我们患了某种疾病(False Positive),总比一个有病的人没有被检查出来(False Negative)要强得多。我们把后面一种情况称为假阴性,也就是“漏报”。误判率越低,则数组越长,所占空间越大。误判率越高则数组越小,所占的空间越小。
应用场景
HTTP 缓存服务器、Web 爬虫等
主要工作是判断一条 URL 是否在现有的 URL 集合之中(可以认为这里的数据量级上亿)。
对于 HTTP 缓存服务器,当本地局域网中的 PC 发起一条 HTTP 请求时,缓存服务器会先查看一下这个 URL 是否已经存在于缓存之中,如果存在的话就没有必要去原始的服务器拉取数据了(为了简单起见,我们假设数据没有发生变化),这样既能节省流量,还能加快访问速度,以提高用户体验。
对于 Web 爬虫,要判断当前正在处理的网页是否已经处理过了,同样需要当前 URL 是否存在于已经处理过的 URL 列表之中。
垃圾邮件过滤
假设邮件服务器通过发送方的邮件域或者 IP 地址对垃圾邮件进行过滤,那么就需要判断当前的邮件域或者 IP 地址是否处于黑名单之中。如果邮件服务器的通信邮件数量非常大(也可以认为数据量级上亿),那么也可以使用 Bloom Filter 算法。