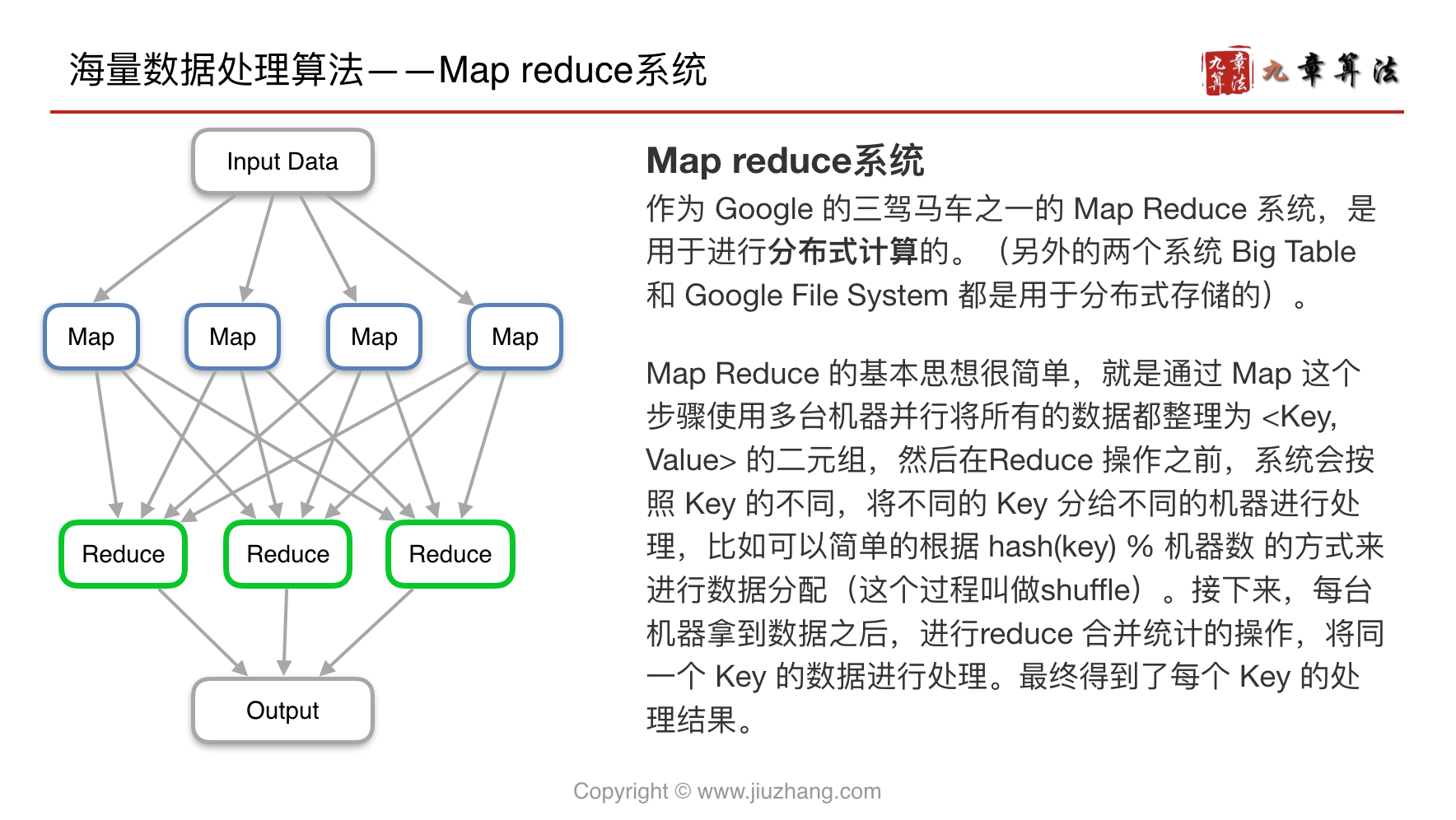
Map Reduce
Map Reduce
那这样的 Map reduce 系统有什么好处呢?
其实 Map Reduce 并没有结余实际上的计算时间总和,但是如果你现在有很多的计算资源(很多台机器),你可以通过 Map Reduce 的框架利用多台机器同时计算,来优化性能进行提速。Map Reduce 是一套通用的分布式计算框架。这样,对于很多类似的问题,工程师并不需要每次都去自己构思如何使用多台机器优化计算的算法,只需要套用这个通用框架,就可以快速的解决问题。
(比如:矩阵分解问题,Page Rank 搜索排序算法)
你可能会有疑问,为什么一定要使用 Map reduce 来分割文件呢,单纯的分割文件分别统计是否可行呢?
其实是不行的。单纯的将文件 1 丢给机器 1,文件 2 丢给机器 2,分别统计 Top K 之后再合并,这种方法是不行的。因为最高频的那一项可能分别出现在文件 1 和文件 2,这样就相当于降低了其出现的频率,可能造成统计结果不对。
95%的题是如何使用 Map Reduce,5%的题是如何设计 Map Reduce
Interviewer: Count the word frequency of a web page?(单词计数)
方法一:单台机器 for+HashMap
优点:简单;
缺点:只有一台机器一慢、内存大小受限
方法二:多台机器 for+HashMap,一台机器合并算最终结果
合并的时候是 Bottle Neck
合并是否也可以并行?可
以什么为标准来划分?机器 or key?key
key 设计无前后依赖性,且系统设计起来简单
MapReduce:
- Map:并行去做
- Reduce:并行合并
master slave,master 控制的
Map Reduce 是一套实现分布式运算的框架
Input
Split
Map
此时不需要合并,只做 key value 映射
传输整理(Shuffle)
Hadoop 运行机制中,将 map 输出进行分区、分组、排序、和合并等处理后作为输入传给 Reducer 的过程,称为 shuffle 过程。
- Partition sort
- Fetch + Merge
Reduce
Output
函数接口
他们的输入和输出必须是 Key Value 形式
Map 输入 key: 文章存储地址 Value:文章内容
Reduce 输入 key: map 输出的 key Value: map 输出的 value
关键:Map 输出的 key value 是什么
原理
传输整理
master 有一个 consistency hash,根据这个一致性哈希来分组,分组后对每个组的内部进行排序(由于结果存在硬盘上,所以采用硬盘上的外排序),排序一般以 key 作为第一关键字、value 作为第二关键字。
Reduce 会把排好序的文件拿到自己的机器上,如几个机器,然后做k 路归并,每个 key 只能被分配到一台机器上
Questions
Q1: Map 多少台机器?Reduce 多少台机器?
- 全由自己决定。一般 1000map,1000 reduce 规模
Q2(加分): 机器越多就越好么?
- Advantage:
- 机器越多,那么每台机器处理的就越少,总处理据越快
- Disadvantage:
- 启动机器的时间相应也变长了。
Q3?(加分): 如果不考虑启动时间,
Reduce 的机器是越多就一定越快么?
- Key 的数目就是 reduce 的上限(Map Reduce 架构的局限性)
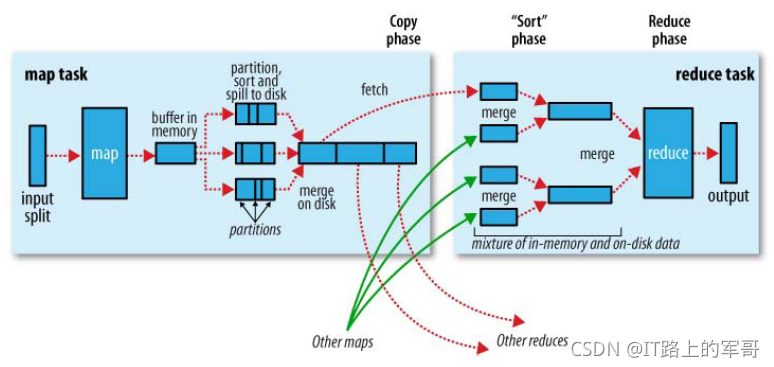
shuffle 阶段又可以分为 Map 端的 shuffle 和 Reduce 端的 shuffle。
Map 端的 shuffle
写磁盘:Map 端会处理输入数据并产生中间结果,这个中间结果会写到本地磁盘,而不是 HDFS。每个 Map 的输出会先写到内存缓冲区中,当写入的数据达到设定的阈值时,系统将会启动一个线程将缓冲区的数据写到磁盘,这个过程叫做 spill。
分区、分组、排序:在 spill 写入之前,会先进行二次排序,首先根据数据所属的 partition 进行排序,然后每个分区(partition)中的数据再按 key 来排序。partition 的目是将记录划分到不同的 Reducer 上去,以期望能够达到负载均衡,以后的 Reducer 就会根据 partition 来读取自己对应的数据。接着运行 combiner(如果设置了的话),combiner 的本质也是一个 Reducer,其目的是对将要写入到磁盘上的文件先进行一次处理,这样,写入到磁盘的数据量就会减少。最后将数据写到本地磁盘产生 spill 文件(spill 文件保存在{mapred.local.dir}指定的目录中,Map 任务结束后就会被删除)。
文件合并:最后,每个 Map 任务可能产生多个溢写文件(spill file),在每个 Map 任务完成前,会通过多路归并算法将这些 spill 文件归并成一个已经分区和排序的输出文件。至此,Map 的 shuffle 过程就结束了。
压缩:在 shuffle 过程中如果压缩被启用,在 map 传出数据传入 Reduce 之前可执行压缩,默认情况下压缩是关闭的,可以将 mapred.compress.map.output 设置为 true 可实现压缩。
Reduce 端的 shuffle
Reduce 端的 shuffle 主要包括三个阶段,copy、sort(merge)和 reduce。
首先要将 Map 端产生的输出文件拷贝到 Reduce 端,但每个 Reducer 如何知道自己应该处理哪些数据呢?因为 Map 端进行 partition 的时候,实际上就相当于指定了每个 Reducer 要处理的数据(partition 就对应了 Reducer),所以 Reducer 在拷贝数据的时候只需拷贝与自己对应的 partition 中的数据即可。每个 Reducer 会处理一个或者多个 partition,但需要先将自己对应的 partition 中的数据从每个 Map 的输出结果中拷贝过来。
接下来就是排序(sort)阶段,也成为合并(merge)阶段,因为这个阶段的主要工作是执行了归并排序。从 Map 端拷贝到 Reduce 端的数据都是有序的,所以很适合归并排序。最终在 Reduce 端生成一个较大的文件作为 Reduce 的输入。MapReduce 编程接口
应用练习
统计频率
key: 字符
value: 1
倒排索引
正排索引:文章序号到关键词列表
倒排索引:关键词到文章序号列表
key: 关键词
value: 文章序号
Reduce 时可以做一个去重操作
Anagram
key: 内部字母排序好的单词
value: 原样字符串
设计
Mapper 和 Reducer 是同时工作还是 Mapper 先工作 Reduceri 再工作?
Mapper 要结束了后 Reducer 才能运行
运行过程中一个 Mapper?或者 Reducer:挂了怎么办?
重新分配一台机器做
Reducer-一个机器 Key 数目特别多怎么办?
加一个 random 后缀,类似 Shard Key,后面再加一个脚本合并
Input 和 Output 存放在哪?
存放在 GFS 里面
Local Disk 上面的 Mapper output data 有没有必要保存在 SFS 上面?要是丢了怎么办?
不需要,丢了重做就好
Mapper 和 Reducer 可以放在同一台机器么?
这样设计并不是特别好,Mapper 和 Reducer 之前都有很多需姜预处理的工作。两台机器可以并行的预处理。
map 的结果会在 map 端进行 sort,这些 map 端就是 hadoop 集群里的 datanode(slave),并不是专门的机器做 sort