Artificial Intelligence
Artificial Intelligence
深度学习 神经网络 机器学习 人工智能
顶会
- ICLR
- NeurIPS
- CVPR
- ICCV
- ACL
- ECCV
Paradigm
The Big Three + 1
这是所有机器学习的根基,根据标签(Label)的存在与否来划分。
- Supervised Learning (有监督学习)
- 定义:有老师教。输入数据 和正确答案 都有。
- 代表:猫狗分类、房价预测。
- Unsupervised Learning (无监督学习)
- 定义:没老师教,自己找规律。只有数据 ,没有 。
- 代表:聚类 (K-Means)、降维 (PCA)。
- Reinforcement Learning (强化学习, RL)
- 定义:从互动中学习。没有现成答案,但做对了有奖励 (Reward),做错了有惩罚。
- 代表:AlphaGo 下围棋、机器人走路、王者荣耀 AI。
- Semi-supervised Learning (半监督学习)
- 定义:一半有老师,一半靠猜。少量数据有标签,大量数据没标签(因为打标签太贵了)。
- 核心:利用没标签的数据来平滑决策边界。
Data-Efficient
这一类方法旨在解决“数据不够”或“数据质量不高”的问题,对比学习就在这里。
- Self-Supervised Learning (自监督学习)
- 地位:目前最重要的范式之一(BERT, GPT, MAE, SimCLR 都属于此类)。
- 定义:自己给自己出题。把数据的一部分(如被遮住的词、被裁剪的图片)作为输入,另一部分作为标签。
- 包含:
- Contrastive Learning (对比学习):如你所知,拉近相似的,推开不相似的。
- Masked Modeling (掩码建模):像 BERT 那样把词挖掉让你填空。
- Transfer Learning (迁移学习)
- 定义:举一反三。在大任务(如 ImageNet 识别)上学好通用知识,然后微调(Fine-tune)到小任务(如识别某种罕见病)。
- 口号:"Don't train from scratch."
- Few-Shot / Zero-Shot Learning (少样本/零样本学习)
- 定义:看一眼就会。只给模型看 1 个或几个例子(甚至不给例子,只给描述),它就能学会分类。
- 现状:GPT-4 等大模型的强项。
- Active Learning (主动学习)
- 定义:不懂就问。模型在训练过程中,主动挑选它最“困惑”的样本,请求人类专家打标签。
- 目的:为了省钱,只标注最有价值的数据。
Task-Centric
你提到的多任务学习属于这里。
- Multi-Task Learning (多任务学习)
- 定义:一心多用。一个模型同时学多个目标(例如推荐系统同时预测“点击率”和“完播率”)。
- 优势:不同任务间共享底层特征,互通有无,防止过拟合。
- Ensemble Learning (集成学习)
- 定义:三个臭皮匠,顶个诸葛亮。训练多个模型(如 XGBoost 里的多棵树),然后投票或取平均。
- 地位:Kaggle 比赛刷分神器。
- Meta-Learning (元学习)
- 定义:Learning to Learn(学会如何学习)。不是学习具体的分类任务,而是学习“如何快速适应一个新任务”的能力。
Process-Oriented
关注**“怎么学”**效率最高。
- Curriculum Learning (课程学习)
- 定义:循序渐进。先给模型看简单的样本(Easy Samples),学好了再给难的(Hard Samples)。像人类上学一样,先学加减,再学微积分。
- Online Learning (在线学习/增量学习)
- 定义:活到老学到老。数据像水流一样源源不断进来,模型实时更新,不用每次都把历史数据重新跑一遍。
- 场景:抖音/TikTok 的推荐算法,必须实时捕捉你的兴趣变化。
- Adversarial Learning (对抗学习)
- 定义:左右互搏。生成器(Generator)造假,判别器(Discriminator)打假,两人博弈中共同进步。
- 代表:GAN (生成对抗网络)。
LLM 时代的“新三样”
随着 ChatGPT 的爆发,这几个词变得极度重要。
- In-Context Learning (上下文学习)
- 定义:不需要更新模型参数(不改权重)。直接在 Prompt 里给几个例子,模型就能照猫画虎地输出结果。
- 本质:这是 LLM 特有的能力,利用 Prompt 激发模型学到的知识。
- Instruction Learning (指令学习 / Instruction Tuning)
- 定义:听懂人话。让模型学会遵循“把这段话翻译成英文”、“解释这个代码”等指令,而不是单纯地续写文本。
- Preference Learning (偏好学习)
- 定义:对齐人类价值观。不仅要答对,还要答得让人类满意(有用、无害)。
- 代表技术:RLHF (Reinforcement Learning from Human Feedback) 和 DPO (Direct Preference Optimization)。
其他特定领域的 Learning
- Metric Learning (度量学习):学习计算两个物体的距离(和对比学习很像,人脸识别常用)。
- Federated Learning (联邦学习):数据不出本地,保护隐私。大家各自在手机上训练,只把更新的梯度上传到云端。
- Dictionary Learning (字典学习):稀疏编码时代的经典,学习一组基向量来表示数据。
总体分类
1. 基础层(算法与模型)
研究如何表示、学习和推理智能。
💡 1.1 机器学习(Machine Learning)
监督学习(Supervised Learning)
无监督学习(Unsupervised Learning)
半监督学习(Semi-supervised Learning)
自监督学习(Self-supervised Learning)
- 对比学习
强化学习(Reinforcement Learning, RL)
元学习(Meta-learning)
联邦学习(Federated Learning)
💡 1.2 深度学习(Deep Learning)
- 卷积神经网络(CNN)
- 循环神经网络(RNN, LSTM, GRU)
- 图神经网络(Graph Neural Network, GNN)
- Transformer、注意力机制(Attention Mechanism)
- 多模态学习(Multimodal Learning)
💡 1.3 生成模型(Generative Models)
- 生成对抗网络(GAN)
- 变分自编码器(VAE)
- 自回归模型(Autoregressive Models)
- Diffusion Models(扩散模型)
- NeRF、Neural Fields
💡 1.4 概率与决策理论
- 贝叶斯方法(Bayesian Methods)
- 马尔可夫决策过程(MDP)
- 多臂老虎机、多智能体系统
2. 感知层(理解世界)
👁️ 2.1 计算机视觉(Computer Vision)
- 图像分类、目标检测、语义分割、实例分割
- 姿态估计、三维重建(SLAM、NeRF)
- 视频理解、图像生成
- 多视图几何与三维感知(3D Vision)
🗣️ 2.2 自然语言处理(Natural Language Processing)
- 语言模型(GPT、BERT、T5)
- 文本生成与理解
- 情感分析、问答系统、对话系统
- 信息抽取与知识图谱
🔊 2.3 语音与音频(Speech & Audio)
- 自动语音识别(ASR)
- 文本转语音(TTS)
- 声纹识别、声音生成、声音事件检测
3. 决策层(做出行动)
🧠 3.1 强化学习与控制(RL & Planning)
- 深度强化学习(DQN, PPO, A3C)
- 多智能体系统(MARL)
- 模型预测控制(MPC)
- 机器人导航与路径规划
🕹️ 3.2 人工智能游戏(Game AI)
- AlphaGo、AlphaZero、MuZero
- 游戏中的策略学习、多智能体博弈
交叉与新兴方向
🤝 多模态智能(Multimodal AI)
图文、视听、视频+文本的联合学习(如 CLIP、GPT-4V、SAM)
🧠 大模型与通用人工智能(LLM & AGI)
GPT、Gemini、Claude 等,研究模型对齐、提示工程、能力迁移。
🧩 解释性与可解释 AI(XAI)
为什么模型做出某个决策,如何增强透明度与信任。
📚 知识图谱与因果推理
结构化知识管理、因果关系建模、科学发现。
🌐 联邦学习与隐私保护(FL & Privacy-preserving ML)
在保证数据隐私的前提下训练模型。
👥 人工智能伦理与社会影响(AI Ethics & Safety)
对齐问题、偏见检测、人工智能治理、AIGC 风险。
应用层分类
- 医疗 AI(Medical AI)
- 金融 AI(金融风控、智能投顾)
- 教育 AI(智能辅导、知识追踪)
- 无人驾驶(Autonomous Driving)
- 人机交互(Human-AI Interaction)
- 具身智能/智能机器人(Embodied AI)
- AIGC(AI Generated Content)
- 智能制造、工业 4.0
其他分类
基于学习策略的分类:
监督学习 Supervised Learning
1)线性回归(Linear Regression):线性回归用于建立输入特征与连续数值目标之间的线性关系模型。它通过拟合一条直线或超平面来进行预测。
2)逻辑回归(Logistic Regression):逻辑回归适用于分类问题,其中目标变量是离散的。它使用逻辑函数(如 sigmoid 函数)来建立输入特征与目标类别之间的关系模型。
3)决策树(Decision Trees):决策树通过构建一系列决策规则来进行分类或回归。它根据特征的不同分割数据,并构建一个树状结构来进行预测。
4)支持向量机(Support Vector Machines,SVM):SVM 是一种用于分类和回归的监督学习算法。它通过寻找一个最优的超平面或者非线性变换,将不同类别的数据样本分隔开。
5)随机森林(Random Forest):随机森林是一种集成学习算法,它结合了多个决策树进行分类或回归。每个决策树基于随机选择的特征子集进行训练,并通过投票或平均来获得最终预测结果。
6)神经网络(Neural Networks):在监督学习中,神经网络接收一组输入数据,并将其传递到网络中的多个神经元层中进行处理。每个神经元都有一组权重,用于加权输入数据。然后,输入数据通过激活函数进行非线性变换,并传递到下一层。这个过程被称为前向传播。在前向传播后,网络产生一个输出,与预期的目标输出进行比较。然后,通过使用损失函数来度量预测输出与目标输出之间的差异。损失函数的目标是最小化预测输出与目标输出之间的误差。接下来,网络使用反向传播算法来更新权重,以减小损失函数。反向传播通过计算损失函数相对于每个权重的梯度,然后沿着梯度的方向更新权重。这个过程不断迭代,直到网络的性能达到满意的程度。
无监督学习 Unsupervised Learning
1)K 均值聚类(K-means Clustering):K 均值聚类是一种常见的聚类算法,用于将数据点划分为预先定义的 K 个簇。算法通过迭代地将数据点分配到最近的质心,并更新质心位置来优化聚类结果。K 均值聚类适用于发现数据中的紧密聚集模式。
2)层次聚类(Hierarchical Clustering):层次聚类是一种将数据点组织成树状结构的聚类方法。它可以基于数据点之间的相似性逐步合并或分割聚类簇。层次聚类有两种主要方法:凝聚层次聚类(自底向上)和分裂层次聚类(自顶向下)。层次聚类适用于发现不同层次的聚类结构。
3)主成分分析(Principal Component Analysis,PCA):主成分分析是一种降维技术,用于从高维数据中提取最重要的特征。它通过找到数据中的主要方差方向,并将数据投影到这些方向上的低维空间中来实现降维。PCA 广泛应用于数据可视化、噪声过滤和特征提取等领域。
4)关联规则学习(Association Rule Learning):关联规则学习用于发现数据集中的项集之间的关联关系。它通过识别频繁项集并生成关联规则来实现。关联规则通常采用"If-Then"的形式,表示数据项之间的关联性。关联规则学习可应用于市场篮子分析、推荐系统等领域。
半监督学习
强化学习
自监督学习
元学习
联邦学习
基于形式
传统机器学习
深度学习
DNN 深度神经网络 ANN 人工神经网络 = DL 深度学习
- CNN 卷积神经网络
- RNN 循环神经网络 LSTM, GRU
- 注意力机制 Transformer, Attention
- GNN 图神经网络
- 多模态学习 Multimodal Learning
生成模型(Generative Models)
- 生成对抗网络(GAN)
- 变分自编码器(VAE)
- 自回归模型(Autoregressive Models)
- 扩散模型 Diffusion Models
- NeRF、Neural Fields
ML Workflow
Problem formulation
Collect & process data
Train & tune models
Deploy models
Monitor
Challenges
- Formulate problem:focus on the most impactful industrial problems(self-service supermarket, self-driving cars)
- Data:high-quality data is scarce,privacy issues
- Train models:models are more and more complex,data-hungry,expensive
- Deploy models:heavy computation is not suitable for real-time inference
- Monitor: data distributions shifts, fairness issues
Machine Learning≈Looking for Function
Different types of Functions
Regression: The function outputs a scalar.
Classification: Given options(classes),the function outputs the correct one.
Structured Learning: create something with structure (image, document)
Framework of ML
Training data:
Testing data:
Training
Function with Unknown Parameters
- Define Loss from Training Data
- Loss is a function of parameters L(b,w)
- Loss: how good a set of values is.
- MAE:
- MSE:
- If y and are both probability distributions Cross-entropy
- Define Loss from Training Data
Optimization:
Gradient Descent
- (Randomly) Pick an initial value
- Compute
- , : learning rate (hyper parameters)
- Update for each batch
Does local minima truly cause the problem?
- Local minima
- global minima
Model Bias: Linear models have severe limitation
All Piecewise Linear Curves = constant + sum of a set of (unlinear)
- Sigmoid:
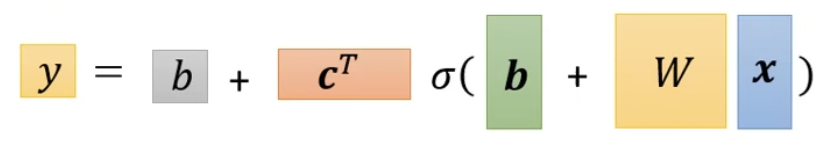
Activation Function
- Sigmoid
- Rectified Linear Unit (ReLU)
Neuron
Neuron Network
Deep Learning
Deep = Many hidden layers
Overfitting
General Guide

Fully-connected
CNN
- Less parameters, sharing parameters
- Less features
- Early stopping
- Regularization
- Dropout
Cross Validation
Training Set
- Training Set
- Validation Set
Optimization
Auto-Regression: KV-Cache
| 优化项 | 解释 | 带来的好处 |
|---|---|---|
| Flash Attention | 利用 CUDA kernel 优化 Softmax-attention 的矩阵乘法,减少内存读写 | 更快、更省内存,适用于长序列 |
| Rotary Positional Encoding (RoPE) | 替代传统位置编码,兼容 KV 缓存并支持无限延展 | 提升泛化能力 |
| Quantization (INT8, FP8, etc.) | 用低精度浮点数代替 FP16/FP32 | 节省显存,提升吞吐量 |
| LoRA / QLoRA | 微调时只训练小矩阵,冻结大部分参数 | 更轻量、高效微调 |
| Weight Tying / Sharing | Embedding 和输出层共享参数 | 降低模型大小 |
| Prefix Caching / Prefill | 将一段 prompt 预编码并缓存 | Chat 场景中节省大量计算(典型如长系统提示) |
Inference 推理
量化
缓存
- KV Cache
剪枝
- Token Pruning
- Model Pruning
- To prune, or not to prune, Google
蒸馏
Token Pruning
好处,无需训练
dart=https://github.com/ZichenWen1/DART