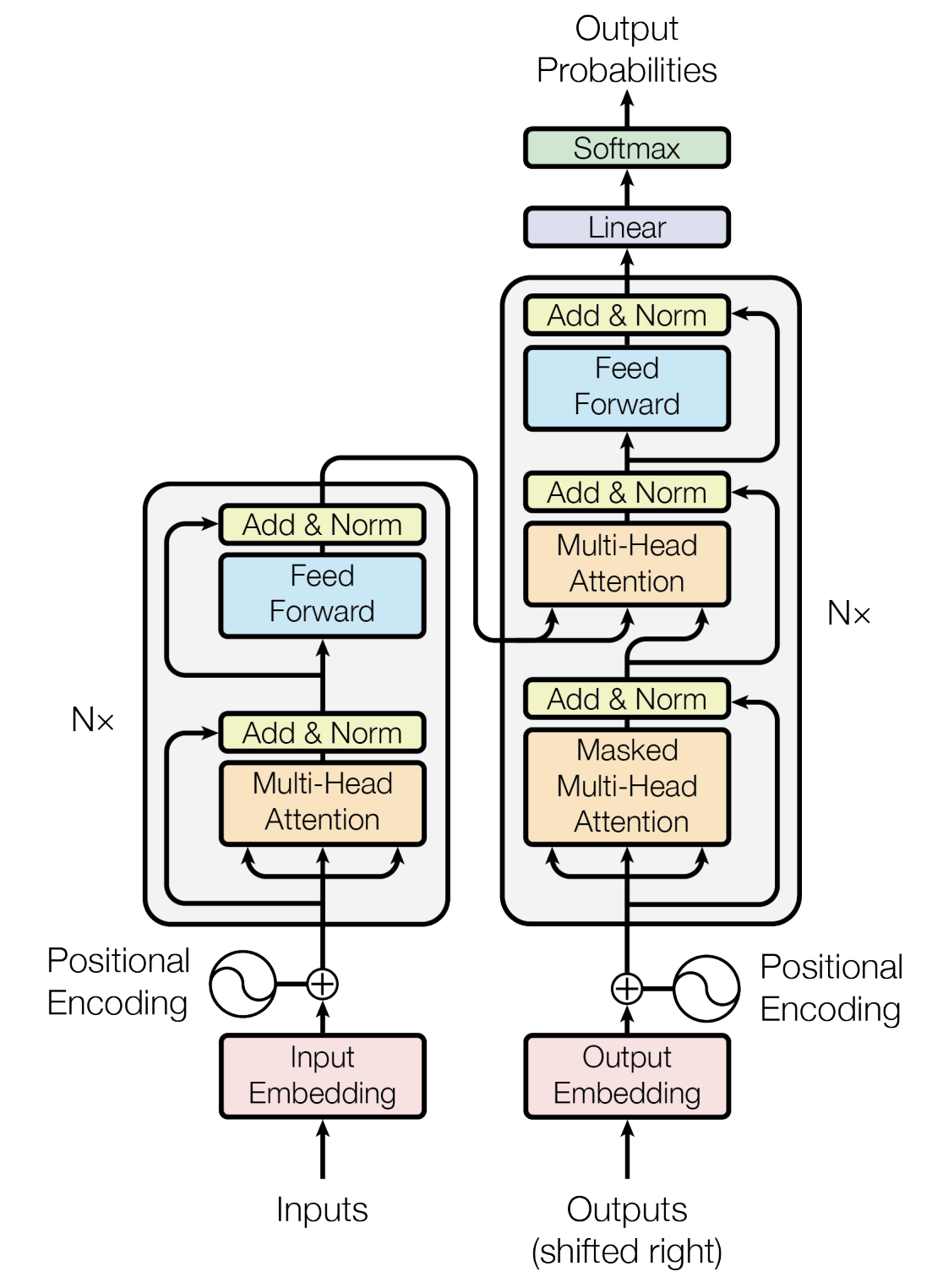
Transformer
Transformer
- Multi-Head Attention
- Self-Attention
- LayerNorm+Residual
- Position Encoding
- FFN (Feed-Forward Network)
| 组件 | 作用 |
|---|---|
| Multi-Head Attention | 并行多个注意力头,捕捉不同语义关系 |
| Self-Attention | 句子内部 token 之间互相关注 |
| LayerNorm + Residual | 加快收敛、稳定训练 |
| Position Encoding | 提供 token 的位置信息(因为注意力是无序的) |
| Feed-Forward Network | 每个位置独立的非线性变换 |
步骤
Tokenization
Input Layer
理解 Token
- Embedding 语言
- Positional Embedding 位置
Transformer Block * N
- Attention 上下文
- Feed Forward
Output Layer
Tokenization
Token list
Byte Pair Encoding (BPE)
无训练参数
https://platform.openai.com/tokenizer
Input Layer
Embedding
把 token 变成向量:意思相近的 Token 会有接近的 Embedding
Token Embedding 是参数,训练时获得
目前的缺点,没有考虑上下文
Positional Embedding
为位置设置向量,拼接到 Embedding 前面
- 可以由人设计
- 可以设成参数
Transformer Block
Attention
Contextualized Token Embedding
考虑上下文
输入一组Embedding=>输出等长Embedding
找出相关的Token
相关性:attention weight
分数=f() (有参数,需要训练得到)
输出以相关性为权的加权平均数
所有Token两两相关性
Attention Matrix
- Causal Attention: 只考虑前面的 Token
Multi-Head Attention 关联性不止一种(一般16组)
Feed Forward
把 MHA 输出的多个向量综合考虑下,出一个向量出来
最后一个 Transformer Block 句尾的向量通过Output Layer
Linear Transform + Softmax 给一个几率分布,知道下一个选哪个 Token 的几率
研究方向
- 加速 Attention 计算
- 达成无限长度的 Attention
- Train short, test long
- 其他类神经网络架构的可能性
产生答案
处理超长文本会是挑战:Attention 要计算两两相似度,是n^2
Cross Attention
结构
- Word Embedding
- Positional encoding (PE)
- Multi-Head Attention (MHA)
- Feed-Forward Network (FFN)
- MLP 全连接神经网络
- 隐藏层12288*4维向量,先放大再提取来过滤信息
- w1 放大4倍
- w2 缩小4倍
- Layer Normalization
Word Embedding
词嵌入:把词变成向量
Self-Attention
自注意力:通过Query、Key、Value三个矩阵计算序列中每个位置对其他位置的关注度。QKV 都是一个东西,所以就是自注意力机制
计算过程:
- 将输入映射为Q、K、V三个矩阵
- 计算注意力权重:
- 允许模型并行处理序列,突破了RNN的顺序限制
后续改进:
- MHA: 将注意力机制并行化,每个头关注不同的表示子空间。
- Multi-Query Attention (MQA): 多个Query头共享同一个Key和Value,减少内存占用
- Grouped-Query Attention (GQA): MQA和MHA的折中方案
- Flash Attention: 通过重新组织计算顺序,大幅降低内存使用
- Sliding Window Attention: 限制注意力窗口大小,提高长序列效率
- Sparse Attention: 只计算部分注意力连接,如Longformer、BigBird
Positional Encoding
位置编码:由于自注意力机制本身不包含位置信息,需要额外添加位置编码。
将每个位置编号,从而每个编号对应一个向量,最终通过结合位置向量和词向量,作为输入embedding,就给每个词都引入了一定的位置信息,这样Attention就可以分辨出不同位置的词了
RoPE(Rotary Position Embedding): 旋转位置编码
- NTK-aware Scaled RoPE
ALiBi(Attention with Linear Biases): 一种位置编码方法,通过线性偏置实现
Xpos
Feed-Forward Network
前馈网络:每个 Transformer 层包含一个两层的全连接网络。
后续改进:
- GLU变体: 使用门控机制,如SwiGLU、GeGLU
- 专家混合 (MoE): 条件激活部分参数,如 Switch Transformer
- 参数高效方法: LoRA、Adapter等减少微调参数
Layer Normalization
层归一化:标准化层输入,稳定训练过程。
后续改进:
- Pre-LN: 将LayerNorm移到残差连接之前,改善训练稳定性
- RMSNorm: 简化LayerNorm计算
- DeepNorm: 专门为深层网络设计的归一化方法
Training Tips
Teacher Forcing
using the ground truth as input when training
There is a mismatch! exposure bias
训练的时候给她看一点错的
Scheduled Sampling
- Original Scheduled Sampling
- for LSTM的,对于Transformer会损失并行能力
- Scheduled Sampling for Transformer
- Parallel Scheduled Sampling
Copy Mechanism
Pointer Network
Copying
Guided Attention
语音识别、语音合成中经常使用
In some tasks,input and output are monotonically aligned. For example,speech recognition,TTS,etc.
Monotonic Attention
Location-aware attention
Beam Search
解决 Greedy Decoding 不是全局最优解
Beam Search 给一个估算的全局最优解
根据任务:
- 确定性任务可以beam search,
- 创造力任务需要加入随机性不要beam search
- 训练的时候加noise或drop out
- decoder 中加入随机性
Sampling
The Curious Case of Neural Text Degeneration https://arxiv.org/abs/1904.09751
Optimizing Evaluation Metrics
Training: minimize cross entropy
Evaluation: BLEU score (不能微分,没法sgd)
遇到无法optimize的loss function,把它当作是RL的reward,把decoder当作rl的agent,用RL硬train就可以了
可以自我介绍一下吗 叫什么 现在在哪里上学 擅长什么不擅长什么 等等
大家好,我是刘大维,目前在UPenn CIS项目读的研二。我之前有一段生信可视化平台