Multimodal Large Language Model
4/3/26Less than 1 minute
Multimodal Large Language Model
类型
- 输入与输出模态不同
- 多模态输入
- 多模态输出
模型
- Flamingo
- IDEFICS
- BLIP
- LLAVA
- Qwen
要素
- Encoder: 各模态的Encoder
- Align Strategy: 不同模态的对齐/融合方式
- LLM(Optional): 以大语言模型为核心的网络
分类
- Dual-Encoder 双塔
- Fusion
- GLIP
- CoCa
- SAM
- FLAVA
- Encoder-Decoder
- Adapted LLM
Visual Language Model
视觉基础模型
- 骨干网络:ViT
- Moco v1, v2: 基于ResNet
- Moco v3: 基于ViT了
自监督基础模型:
- DINO(对比式)
- MAE(生成式)
分割基础模型:
- SAM
CV 很多方法都是源于 NLP 的思路
图像 Encoder: DINO, MAE
图像文本 Pair Encoder: CLIP
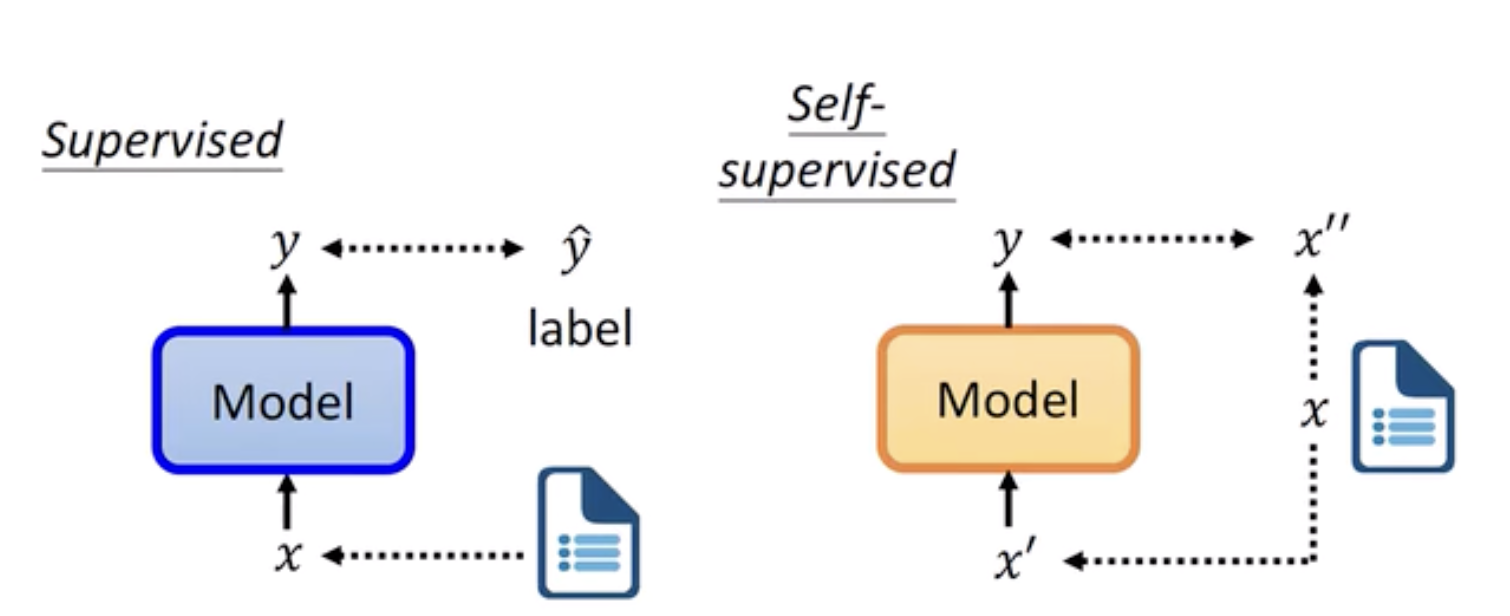
自监督学习 (Self-supervised Learning)
定义:Predict parts of input data from other parts, using the data's inherent structure instead of explicit labels
- 基于前置任务
- 位置预测(上下文)
- 旋转预测
- 上色
- 聚类预测
- 基于对比学习
- 创建pair样本
- 基于掩码重建