Sample
Sample
To help you with reviewing the concepts studied in the lectures, I have put together some sample review questions that could be helpful for your exam preparation. (Some of these questions are also available on the slides or shown during class.)
Please try solving these questions on your own. We will discuss the answers at a later time. Hope it helps.
Lecture 2: Processes & Threads
Q1)
Alice has just learnt about the fork() system call and is eager to put it to practice. She writes the following program:
int main(void){
int i;
int N = 3;
for (i = 0; i < N; i++){
pid_t pid = fork();
if (pid < 0) {
fprintf(stderr, "Fork failed!\n");
exit(1);
} else if (pid == 0) {
printf(“I am child %d\n", i);
} else {
printf("Child %d is created\n", i);
}
}
return 0;
}Assuming all system calls are successful.
a) How many processes are created in total (including the main process)? Explain why.
6=3+2+1
b) Can you generalize your solution to N child processes (instead of exactly 3)?
N+N-1+N-2+...+1=(N+1)*N/2
c) Does your answer change if we add an exit() between Line 10 and 11? Explain.
d) Suppose the above program (the original one, without the change in (c)) is run on a machine with 8 cores. What is the maximum number of processes that can run truly concurrently, assuming any given value of N?
e) Does your answer in (d) change if we add a wait() between Lines 13 and 14? Explain.
Q2)
In class, we have discussed that there are several scheduling policies for scheduling processes. Below are some common examples:
First Come First Served (FCFS) -- also known as FIFO: A process that arrives at the system earlier is scheduled before another process that arrives later. By definition, FCFS is non-preemptive: once started, a process will be executed until completion without being preempted by another process.
Non-preemptive Shortest Job First (SJF): A process that has the shortest total execution time is executed first. Once a process begins execution, it will not be preempted by another process until completion.
Shortest Remaining Time First (SRTF) -- also known as Preemptive SJF: At any given time, the process with the smallest remaining execution time until completion is executed first. By definition, this policy is preemptive: if a new process B with a smaller execution time than the remaining execution time of the currently running process A, then A will be preempted by B.
Preemptive Fixed Priority (FP): Each process is assigned a static priority. At any point in time, the process that has the highest priority is executed. In this preemptive version, a higher-priority process B which arrives while a lower-priority process A is running, then B will preempt A.
Non-preemptive FP (NP-FP): Like in FP, a higher priority process is executed before a lower priority one; however, once a process begins its execution, it cannot be preempted.
Preemptive Earliest Deadline First (EDF): Each process has an absolute deadline, defined as the time at which the process must complete. At any point in time, the process with the smallest absolute deadline is executed first.
Non-preemptive EDF (NP-EDF): Similar to EDF, except that once a process begins its execution, it cannot be preempted by another process (including ones with shorter deadlines).
Consider the following 5 processes, where a larger priority value indicates higher priority.
- P1: Arrival time = 0, Total execution time = 5, Priority = 3, Absolute deadline = 10
- P2: Arrival time = 1, Total execution time = 3, Priority = 2, Absolute deadline = 8
- P3: Arrival time = 3, Total execution time = 4, Priority = 1, Absolute deadline = 13
- P4: Arrival time = 4, Total execution time = 3, Priority = 4, Absolute deadline = 7
- P5: Arrival time = 6, Total execution time = 2, Priority = 5, Absolute deadline = 9
Assuming that the system has only one CPU core. For each scheduling policy above, draw the schedule timeline for each process. You may assume that all processes execute CPU instructions and do not block, and that the overhead for context switching is negligible (takes zero time).
Lecture 3: System calls
Q1. Which of the following IA-32 instructions is used for entering the kernel?
- a) fprem
- b) smsw
- c) sysenter
- d) enter
Q2. Suppose a thread T is running on CPU core X, and the thread blocks. What happens on core X? Select the correct answer(s) from below.
- a) The core does nothing until T is unblocked
- b) The core switches to running another thread, if possible.
- c) The core terminates T
- d) The core shuts down
Q3. How many system calls does Linux have approximately?
- a) 10 to 20
- b) 80 to 100
- c) 300 to 500
- d) 900 to 1200
Q4. How do the read and write system calls identify the file to be read from, or written to?
- a) By its name
- b) By its inode number
- c) By a file handle
- d) Implicitly - they operate on the file that has been opened the most recently
Q5. Which of the following is a difference between user mode and kernel mode?
a) Certain instructions are only available in kernel mode
b) The CPU runs faster in kernel mode
c) Normal process memory is not accessible in kernel mode
d) Peripherals can only be accessed from user mode
Lecture 4: Concurrency control and synchronization
Q1)
Charlie's company runs a cluster of machines that maintain a shared bank account database. Each machine is responsible for storing accounts of a set of customers (called local users), and it can serve transactions (e.g., money transfer) between any two users, regardless of where the users' accounts are stored.
The company has been receiving complaints about money missing in customers’ accounts. After some investigation, Charlie found out that it was due to race conditions. Having learnt about the interrupt disabling technique and Lamport's Bakery algorithm from CIS 5050, he decided to use them for his company’s system.
Later, a customer, Alice, still complains that some money has disappeared from her account (!).
Do you believe Alice? If so, why? If not, why not?
Q2)
Consider the Quiz question in class:
#include <stdio.h>
#include <pthread.h>
const int M = 1000000;
volatile int count = 0;
void *test(void *arg) {
for (int j=0; j<M; j++) count = count + 1;
return NULL;
}
int main(void) {
pthread_t thread0, thread1, thread2;
pthread_create(&thread0, NULL, test, NULL);
pthread_create(&thread1, NULL, test, NULL);
pthread_create(&thread2, NULL, test, NULL);
pthread_join(thread0, NULL);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
printf("count = %d\n", count);
return 0;
}In class, we already discussed that the minimum value of the program output is 2.
- a) Explain why the minimum value can neither 0 nor 1?
- b) Can you give an example execution scenario that will produce the minimum value 2?
- c) Suppose that, instead of 3 child threads as shown in the code, the main thread creates 20 child threads, each of which executes the same "test" thread function. What would be the maximum and minimum output of your program? Explain.
(We discussed all these before, but I wanted to make sure you get it on your own.)
Q3)
In class, we use TSL to achieve mutual exclusion for the critical section, as below.
int lock = 0;
void transferMoney(customer A, customer B, int amount) {
while (testAndSet(&lock) == 1) /* busy-wait */ ;
int balanceA = getBalance(A);
int balanceB = getBalance(B);
setBalance(B, balanceB + amount);
setBalance(A, balanceA - amount);
lock = 0;
}How would you protect the critical section with a CAS instruction instead of a TSL?
Q4)
Slide 20 of Lecture 4 shows our first attempt of the Lamport's Bakery algorithm, which does not work. Using two threads, construct an execution scenario where mutual exclusion is violated.
In your own words, explain why the next slide (Slide 21) solves this problem through the choosing[] variable.
Q5)
Consider the Counting semaphore implementations that we have on Slide 43-46 (all the attempts). Please make sure that you understand the problem with each of these implementations.
Q6)
On Slide 34 (How to implement a semaphore, Attempt #3), we have a solution using interrupt disabling technique. As we discussed before, this will only work with a single core. To make it work in multicore, we can use special instructions instead. Can you change the solution to use a CAS instruction instead of using the cli()/sti()?
Q7)
In class, we have studied deadlock and livelock problems. In your own words, describe one commonality and one difference between the two?
Q8)
In your own words, explain why we cannot use a single counting semaphore (and a binary semaphore) to implement the Producer-Consumer problem in class?
Q9)
One Slide 75, explain why the program is written for Hoare monitors? What would you change to ensure that it work under Mesa monitors as well.
Q10)
In Slide 74, we say that Hoare monitors are good for proofs whereas Mesa monitors can be efficient. In your own words, explain why/how Mesa monitors are more efficient on average.
Q11)
Another benefit of semaphores that we did not discuss in class is that they can be used to enforce orders of execution among threads. Using a semaphore, describe how you can use it to enforce a thread T1 to always execute and finish before thread T2 and thread T3 can start, and thread P2 and P3 must be able to run concurrently. (You may assume each thread takes a finite amount of time and execute only once.)
Lecture 6: Communication
A) Design question:
Elizabeth works for fun-comics.com, a company that sells popular comic books, which frequently attract many customers. She is tasked with redesigning the company's webserver as it has been experiencing very poor performance, despite already running on a powerful 64-core machine. After some investigation, Elizabeth discovers that the server use only a single thread and that it is not event-driven. Having taken CIS 5050 at Penn, Elizabeth reimplements the company's webserver using a multi-threaded architecture, just like the one she studied in class.
After switching to Elizabeth's new webserver, however, the company still experiences slow performance problem, sometimes even worse than before (!).
Q1) Name one reason for why this might happen.
Q2) Can you propose a simple fix to the webserver without changing its multi-threaded architecture to mitigate the problem?
Elizabeth decides that an event-driven server should fix the performance issue once and for all. So she adapts the event-driven server example from the slides in class for her webserver. Unexpectedly, the throughput does not improve but sometimes even drops below that of her multi-threaded server. Elizabeth is at a loss!
Q3) Can you help Elizabeth identify a potential cause?
Q4) How would you change her server to solve this problem?
B) Multiple choice questions
Q1. Which of the following is not a layer of the OSI model?
- (a) Session
- (b) Presentation
- (c) Datalink
- (d) Logical
Q2. Which of the following is not a difference between stream sockets and datagram sockets?
- a) Data is sent as messages in datagram sockets, and as a stream of bytes in stream sockets
- b) Message delivery is reliable with stream sockets, but not with datagram sockets
- c) Port numbers are supported for stream sockets, but not for datagram sockets
- d) Stream sockets guarantee data is delivered in order, datagram sockets do not
Q3. With little-endian encoding, which comes first?
- a) The lowest-order byte
- b) The highest-order byte
- c) The byte in the middle
- d) A random byte
Q4. Which type of sockets is best for the following use cases? Why?
- a) Voice over IP
- b) Accessing your Path@Penn to update course registration
- c) Transferring large files
- d) Looking up a name in a directory
Lecture 7: Remote procedure calls
Q1.
Which of the following is true about an RPC and a local function call?
- (a) RPCs require extra parameters to identify the server.
- (b) RPCs typically have higher latency.
- (c) RPCs can only support functions with call-by-value semantics.
- (d) RPCs can fail whereas local functions do not
Q2.
To reduce overhead, Alice’s program first calls an asynchronous RPC to a server, then it waits until the server returns a result using another asynchronous RPC. Does this approach achieve her goal? Why and why not?
Q3.
Can you implement an RPC using UDP? If so, how? If not, why not?
Q4.
Bob notices his program runs too slowly on his single-core machine, so he decides to use RPC to run it on a remote (more powerful) multi-core server. Suppose that
- The program takes N milliseconds to run on Bob's machine, where N is the input size.
- The program is fully concurrent and would take N/m milliseconds to run on the remote server with m cores (where N is the input size).
- Marshalling and unmarshalling of a message (on the client stub or server stub) each take (5 + N/80) milliseconds.
- The one-way latency between the server and Bob's machine is approximately 35 milliseconds.
- The waiting time of the RPC request at the server is negligible.
a) Is running the service as an RPC always preferred to running it locally if the server (has more cores) is more powerful than the local machine? If yes, why? If no, why not?
b) Suppose Bob's primary goal is to improve latency performance. Assuming that m = 20. Under which conditions of N should Bob use RPC (instead of running it locally)?
c) Suppose Bob decides that RPC is the right approach. Describe how the latency performance of the program when using RPC changes as we increase the speed of the remote server? Is there a minimum latency?
Lecture 8: Naming
Q1.
Name one advantage and one disadvantage of directory-based against directory-less architecture.
Q2.
Name one benefit and a drawback of anycast DNS.
Q3.
In your own words, explain the strength and weakness of the two naming resolution methods studied in class.
Q4.
True/False questions
- a) In asynchronous systems, flooding guarantees a request will reach all nodes in the network if there is no network partition
- b) In iterative DNS naming resolution, the root servers retain no state of the client requests
- c) Anycast DNS guarantees globally consistent answers for the same request
- d) DNSSEC can defend against DDoS attacks
- e) DNSSEC provides authenticity but not confidentiality
- f) In Akamai, small TTL is used to improve latency
Lecture 9: Clock synchronization
Q1.
In your own words, describe one similarity and one difference between Lamport clock and vector clock.
Q2.
In your own words, name one advantage and one disadvantage of Lamport clock compared to vector clock.
Q3.
Consider a system with 3 nodes A, B, C. Using similar notation as in the example on the slides, the following timeline shows the events and messages that happen in the system. Here, each green circle represents an event (which could be a local event, the sending of a message, or the receipt of a message).
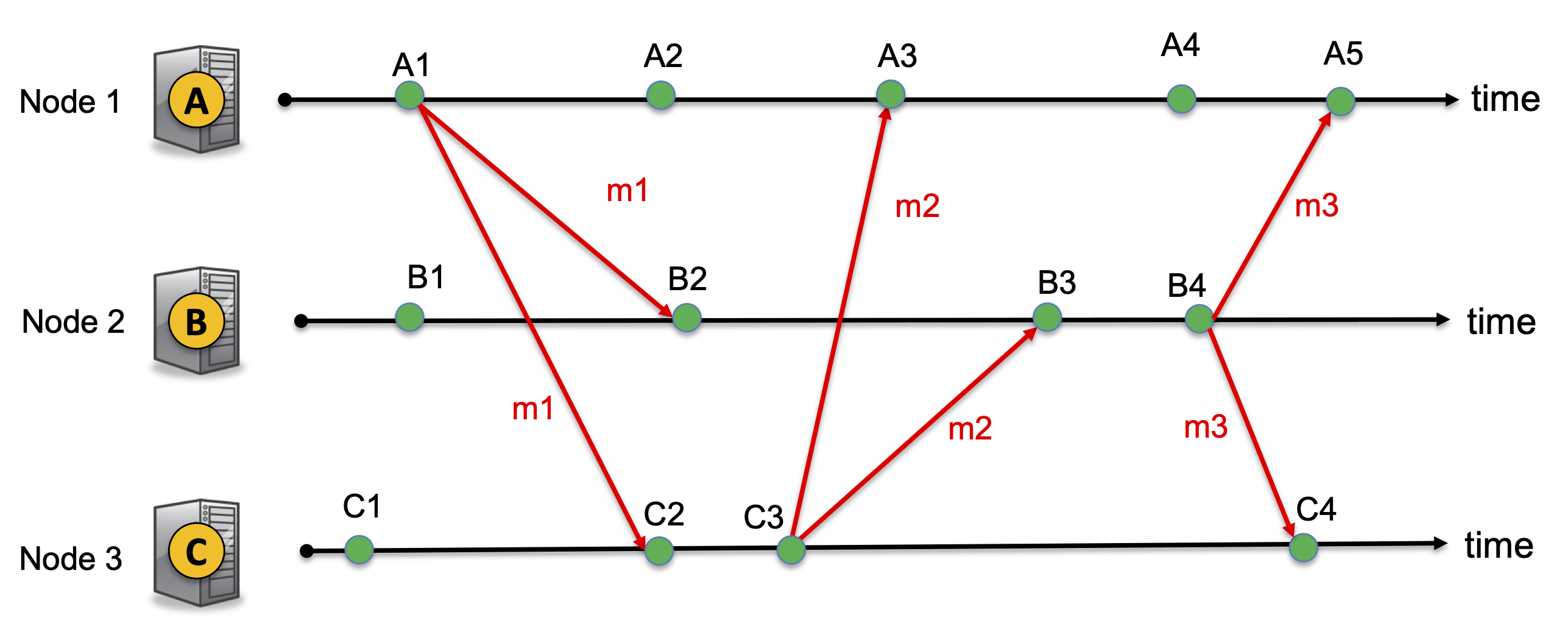
Indicate on the above timeline the vector clock at each node when each event occurs and the vector clock attached with each message.
Q4)
In a distributed system that assigns Lamport clock L(e) and Vector clock V(e) to events. Which of the following statements are true.
- a) If L(a) < L(b), then a --> b
- b) If V(a) < V(b), then a --> b
- c) If L(a) < L(b), then V(a) < V(b)
- d) If V(a) and V(b) are incomparable, events a and b are guaranteed to take place at the same physical time
- e) If V(a) < V(b), then a occurs before b in real time
- f) Logical clocks track ordering among events whereas physical clock tracks physical time
- g) It is always strictly better to use Vector clock than to use Lamport clock for ordering events because Vector clock captures causality whereas Lamport clock does not
Lecture 10: Group communication
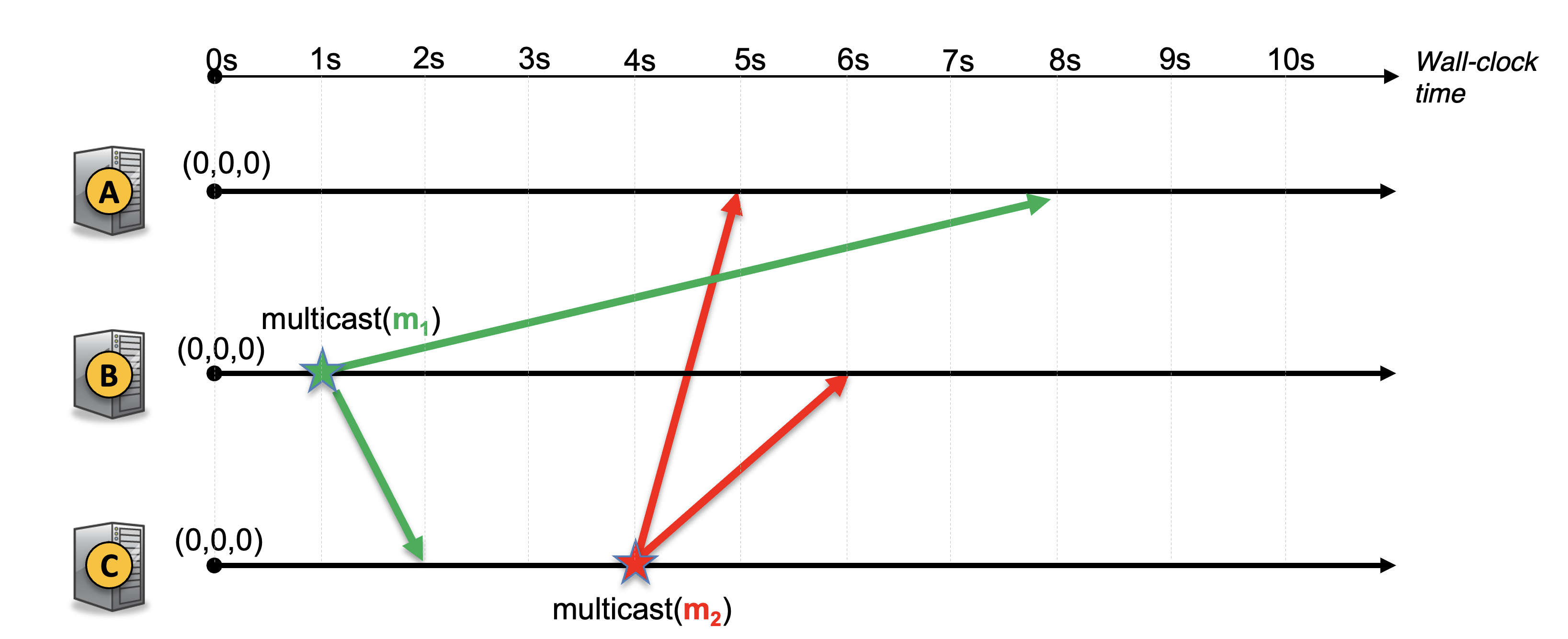
Q1)
Name an advantage and a disadvantage of the gossiping protocol
Q2)
Consider the causally ordered multicast system with 3 nodes below. Describe what happens at each node when a message is sent or received. In particular, indicate on the timeline when the vector clock is updated and when a message is delivered. (Please refer to the causally ordered multicast at the end of the Clock synchronization lecture.)