Linear Regression
Linear Regression
最简单的算法,但是要讲三周
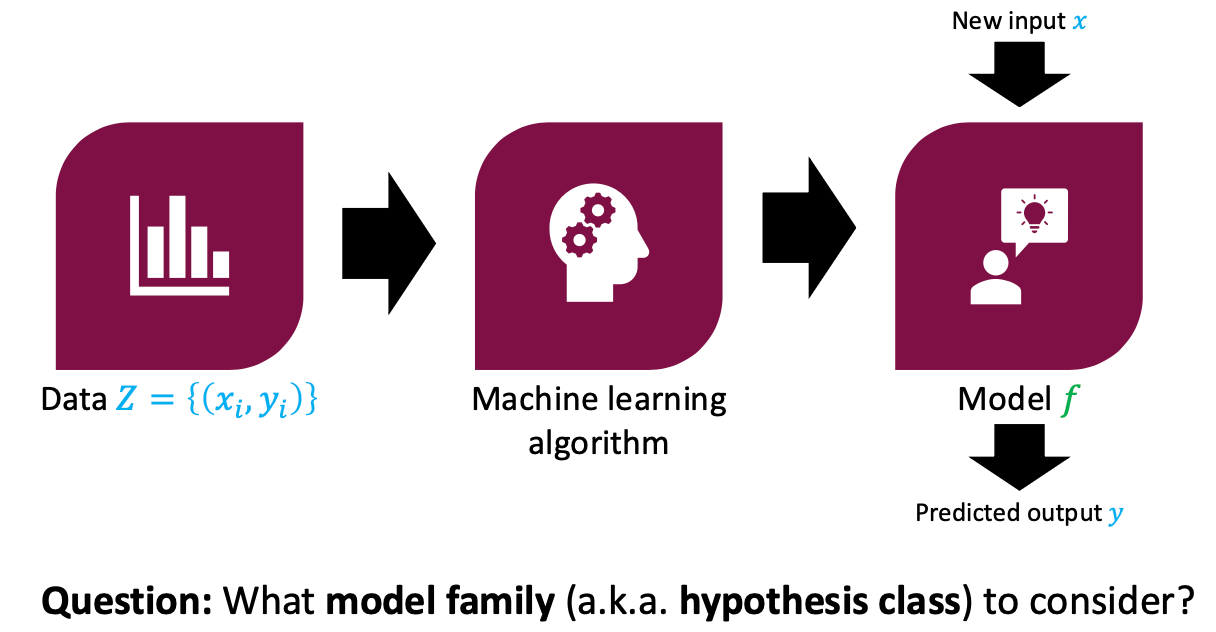
Supervised Learning
Data
Machine learning algorithm
Model
New input => Model => Predicted output
Question: What model family (aka hypothesis class) to consider?
Linear Functions
Consider the space of linear functions defined by
- is called an input (a.k.a. features or covariates)
- is called the parameters (a.k.a. parameter vector)
- is called the label (a.k.a. output or response)
Linear Regression Problem
- Input: Dataset
- Output: A linear function that minimizes the MSE
Loss Function
Mean sqaured error (MSE)
Computationally convenient and works well in practice
True Function
- Mean absolute error
- Mean relative error
- score
- Pearson correlation
- Rank-order correlation
Feature Maps
Linear Regression When Data is Non-Linear?
Quadratic Feature Map
Training vs. Test Data
- • Training data: Examples 𝑍 = 𝑥, 𝑦 used to fit our model
- • Test data: New inputs 𝑥 whose labels 𝑦 we want to predict
Capacity of a model family captures "complexity" of data it can fit
- Higher capacity -> more likely tour
Effectively changes the hypothesis space! This is a powerful strategy for encoding “prior knowledge” about the function we are looking to approximate.
Assessing Underfitting & Overfitting
Training/Test Split
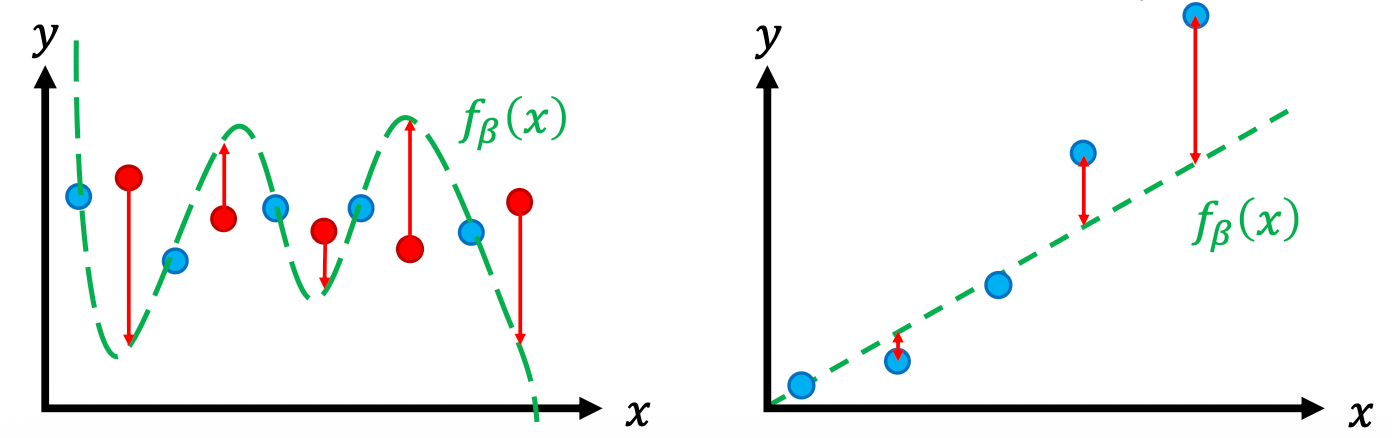
Overfitting (high variance)
- • High capacity model capable of fitting complex data
- • Insufficient data to constrain it
Underfitting (high bias)
- • Low capacity model that can only fit simple data
- • Sufficient data but poor fit
How to fix undercutting/overfitting
- Choose the right model
Regularization
Modifying the loss function
L2
Original loss+regularization
Intuition on L2 Regularization
Encourages "simple" functions
pulls coefficient to 0
L1
Hyperparameter Tuning & Model Selection
- training data
- val data
- test data
Choice of Learning Rate
L2 Regularized Linear Regressions
weight decay that encourages to be small
Minimizing the MSE Loss
- • Closed-form solution: Compute using matrix operations
- • Optimization-based solution: Search over candidate 𝛽
Closed-form solution
Stochastic gradient descent
Iterative Optimization Algorithms
Iteratively optimize 𝛽
- • Initialize 𝛽1 ← Init …
- • For some number of iterations 𝑇, update 𝛽𝑡 ← Step(… )
- • Return 𝛽𝑇