Neural Network
Neural Network
Feed-Forward Neural Network
- Signals move in one direction - forward - with no cycles or loops.
- Also called Multi-Layer Perceptrons (MLP).
- Input Layers
- Hidden layers
- Output Layers
Matrix Notation
- 1-layer Neural Net: 𝑦 = 𝑊 1𝑥
- 2-layer Neural Net: 𝑦 = 𝑊 2𝑔(𝑊 1𝑥)
- 3-layer Neural Net: 𝑦 = 𝑊 3𝑔(𝑊 2𝑔(𝑊 1𝑥))
𝑔 is a non-linear activation function for hidden layers
Non-Linearity
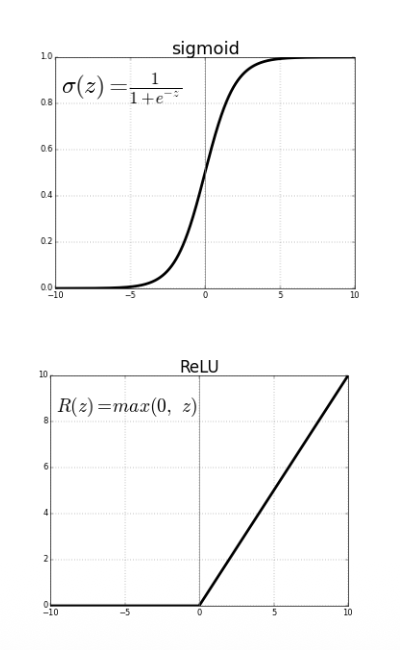
- Sigmoid activation function:
- • Outputs values between 0 and 1
- • Probability of neuron firing/activated
- • ReLU (Rectified Linear Unit):
- • Efficient computation
- • Doesn’t saturate
- • Most commonly used today
Why Non-Linearity?
Q: What if we try to build a neural network without one?
- 2-layer Neural Net: 𝑦 = 𝑊 2𝑔(𝑊 1𝑥) 𝑦 = 𝑊 2𝑊 1𝑥
- 3-layer Neural Net: 𝑦 = 𝑊 3𝑔(𝑊 2𝑔(𝑊 1𝑥)) 𝑦 = 𝑊 3𝑊 2𝑊 1𝑥
A: We would end up with linear classifier!
Non-Linearities are important for learning features/representations with increasing levels of complexity
Model Capacity
Capacity of a feed-forward neural network is affected by both
- Depth: number of hidden layers
- Width: number of neurons in each hidden layer
More neurons = more capacity
Loss functions
Same as single-layer models (i.e., linear and logistic regression)
Regression:
- MSE loss:
Classification:
Binary cross entropy for binary classification:
Cross entropy for multi-class classification:
Optimization
Solve for 𝜃∗= argmin𝜃𝐿( ො𝑦, 𝑦)
Q: Don’t I have to optimize differently for different 𝐿(·)?
A: No, just use gradient descent. It is the most general optimization
approach we know.
Q: But what if 𝐿(·) is non-convex in 𝑊?
A: It almost surely is. Do gradient descent anyway. Just make sure
everything is differentiable.
Stochastic Gradient Descent
Back-Propagation for Computing Gradients
Neural network tips and tricks
- Optimization
- Activation Functions
- Managing Weights
- Dropout
- Managing Training
Optimization
Challenges
- Narrow Valleys
- Saddle Points
Accelerated Gradient Descent
Vanilla gradient descent:
𝜃 ← 𝜃 − 𝛼 ⋅ ∇𝜃𝐿 𝑓 𝜃 𝑥 , 𝑦
Accelerated gradient descent (momentum):
𝜌 ← 𝜇 ⋅ 𝜌 − 𝛼 ⋅ ∇𝜃𝐿 𝑓 𝜃 𝑥 , 𝑦
𝜃 ← 𝜃 + 𝜌
Nesterov Momentum
Adaptive Learning Rates
Activation Functions
Historical Activation Functions
- sigmoid
- tanh
Vanishing Gradient Problem
- The gradient of the sigmoid function is often nearly zero
- • Recall: In backpropagation, gradients are products of local gradients
- • Quickly multiply to zero!
- • Early layers update very slowly
ReLU Activation
Activation function
𝑔 𝑧 = max 0, 𝑧
• Gradient now positive on the entire region 𝑧 ≥ 0
• Significant performance gains for deep neural networks
Leaky ReLU Activation
Managing Weights
Weight Initialization
Zero initialization: Very bad choice!
- • All neurons 𝑧𝑖 = 𝑔 𝑤𝑖⊤𝑥 in a given layer remain identical
- • Intuition: They start out equal, so their gradients are equal!
Long history of initialization tricks for 𝑊 𝑗 based on “fan in” 𝑑in
- • Here, 𝑑in is the dimension of the input of layer 𝑊 𝑗
- • Intuition: Keep initial layer inputs 𝑧 𝑗 in the “linear” part of sigmoid
- • Note: Initialize intercept term to 0
• Kaiming initialization (also called “He initialization”)
- • For ReLU activations, use 𝑊 𝑗∼ 𝑁 0, 2 𝑑in
• Xavier initialization
- • For tanh activations, use 𝑊 𝑗∼ 𝑁 0, 1 𝑑in+𝑑out (𝑑out is output dimension)
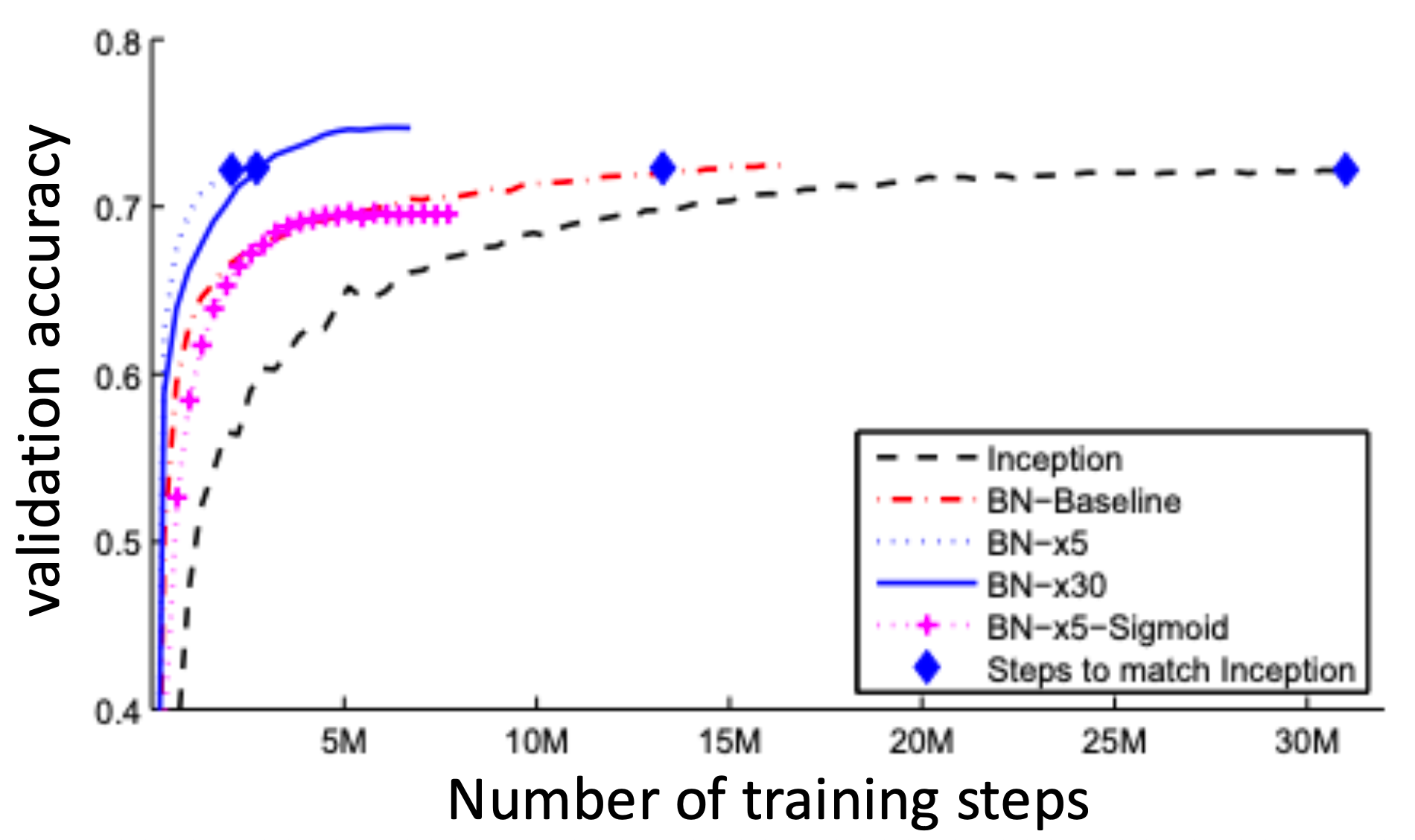
Batch Normalization
Problem
- • During learning, the distribution of inputs to each layer are shifting (since the layers below are also updating)
- • This cause the objective to have a lot irregularity and hard to take large steps in the loss landscape
• Solution
- • As with feature standardization, standardize inputs to each layer to 𝑁 0, 𝐼
- • Batch norm: Compute mean and standard deviation of current minibatch and use it to normalize the current layer (this is differentiable!)
- • Note: Needs nontrivial mini-batches or will divide by zero
- • Apply after every layer (typically before activation)
Regularization
Can use 𝐿1 and 𝐿2 regularization as before
- • As before, do not regularize any of the intercept terms!
- • 𝐿2 regularization more common
Applied to “unrolled” weight matrices
• Equivalently, Frobenius norm