Models
Models
LeNet
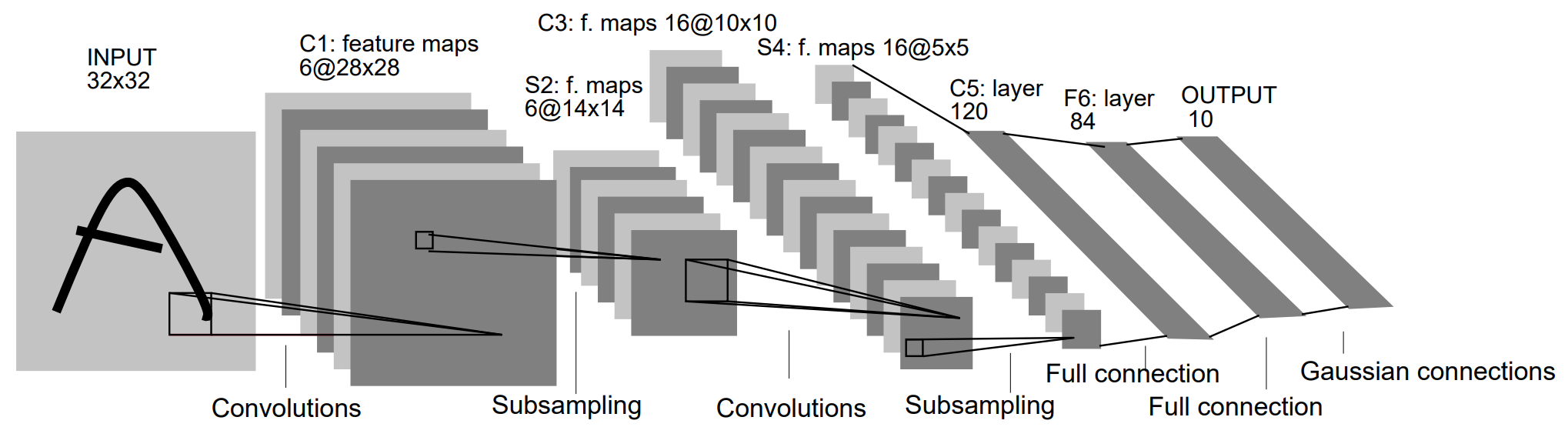
在深度学习的发展史上,LeNet(又称LeNet-5)是一个里程碑式的模型。
Input: 1×32×32 图像(如手写数字)
C1: 卷积层,6个5×5卷积核 → 输出6×28×28
S2: 平均池化层 → 输出6×14×14
C3: 卷积层,16个5×5卷积核 → 输出16×10×10
S4: 平均池化层 → 输出16×5×5
C5: 卷积层,120个5×5卷积核 → 输出120×1×1(相当于全连接)
F6: 全连接层,输出84个神经元
Output: 全连接层,输出10类(数字0-9的概率)
注意: 输入为32×32图像(MNIST是28×28,用zero-padding补足) 使用平均池化(Average Pooling)而非现代常见的最大池化(Max Pooling) 激活函数为Sigmoid或tanh,而非ReLU
LeNet 最初是为美国邮政局开发,用于识别手写邮政编码,是卷积神经网络(CNN)首次成功应用于现实世界问题。它在标准的 MNIST 数据集上取得了超过 99.2% 的准确率,远超当时的传统算法。与依赖人工特征设计的方法不同,LeNet 能通过卷积核自动学习图像特征,省去了手动构造特征的繁琐过程。它结构简单、效率高、准确率高,堪称 CNN 发展史上的里程碑。LeNet-5 首次系统性地引入了 Padding、卷积、池化和全连接等关键结构,这些核心思想至今仍是现代深度学习网络设计的基础。
AlexNet
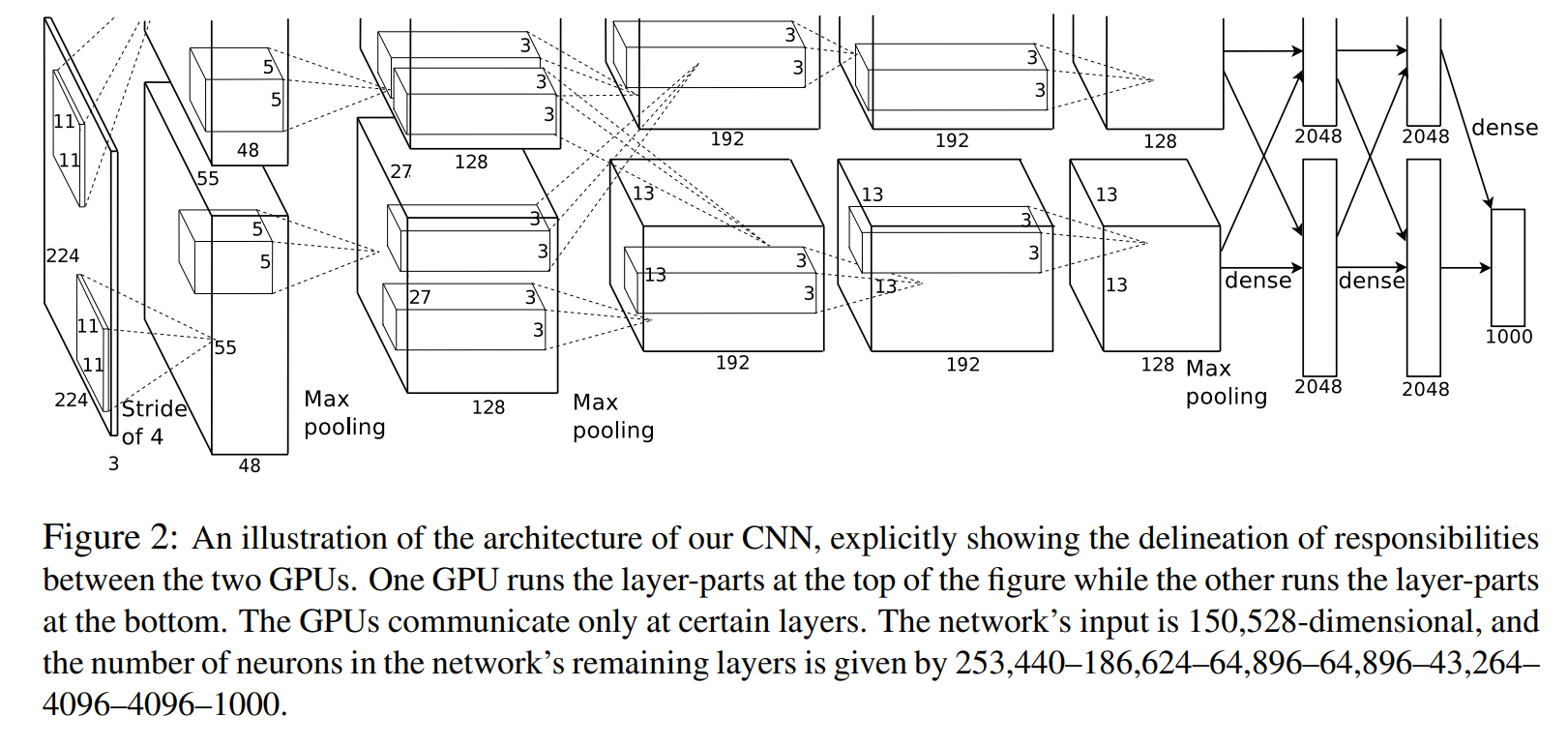
ImageNet
创新点
- 使用ReLU激活函数: 在当时,Sigmoid或Tanh是主流激活函数。AlexNet大胆采用了ReLU。相比Sigmoid,ReLU训练更快,不易梯度消失。
- 使用Dropout防止过拟合: 在全连接层引入Dropout技术,训练时随机丢弃部分神经元,大大减少了过拟合风险。
- GPU并行训练: AlexNet使用两个GPU训练网络的不同部分,这在当时是很创新的做法,大大提升了训练效率。
- 局部响应归一化(LRN): 在前两层使用了LRN来增强ReLU的响应效果,尽管这一技术后来被Batch Normalization取代,但在当时有效提升了模型性能。
- 图像增强技术: AlexNet进行了数据增强,随机从256×256的原始图像中截取224×224大小区域,并以50%的概率做水平翻转,并且进行了光照扰动图像增强。
GoogLeNet
意义
多尺度并行卷积(Inception模块):
Inception模块通过并行使用不同尺寸的卷积核(1x1、3x3、5x5)和池化操作,同时捕捉不同尺度的特征。这种设计突破了传统堆叠单一卷积层的模式,显著提升了模型的特征表达能力。
1x1卷积的革新应用:
利用1x1卷积进行通道降维和非线性增强(1×1卷积后的激活引入非线性)。这一技术成为后续模型设计的标配。
VGGNet
在 2014 年的 ImageNet 挑战中,VGG-19 在验证集上达到 24.8% 的 Top-1 错误率和 7.5% 的 Top-5 错误率,成绩优越。此后,VGG 系列迅速成为计算机视觉领域的基准模型之一。
VGGNet标准化了卷积核(3×3)和池化层(2×2 最大池化层)。这种简洁统一的设计,基本成为了之后卷积神经网络的标准配置。
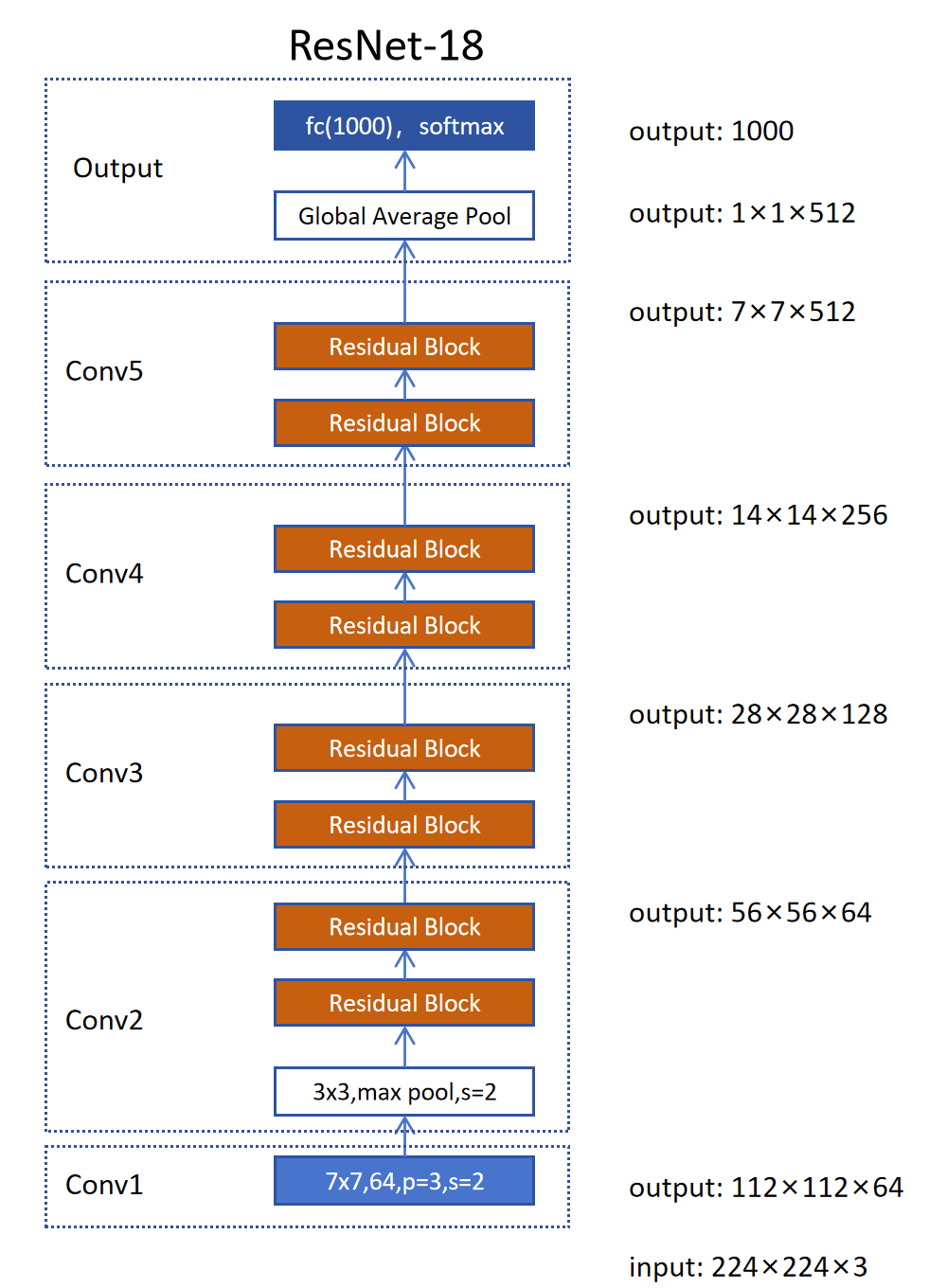
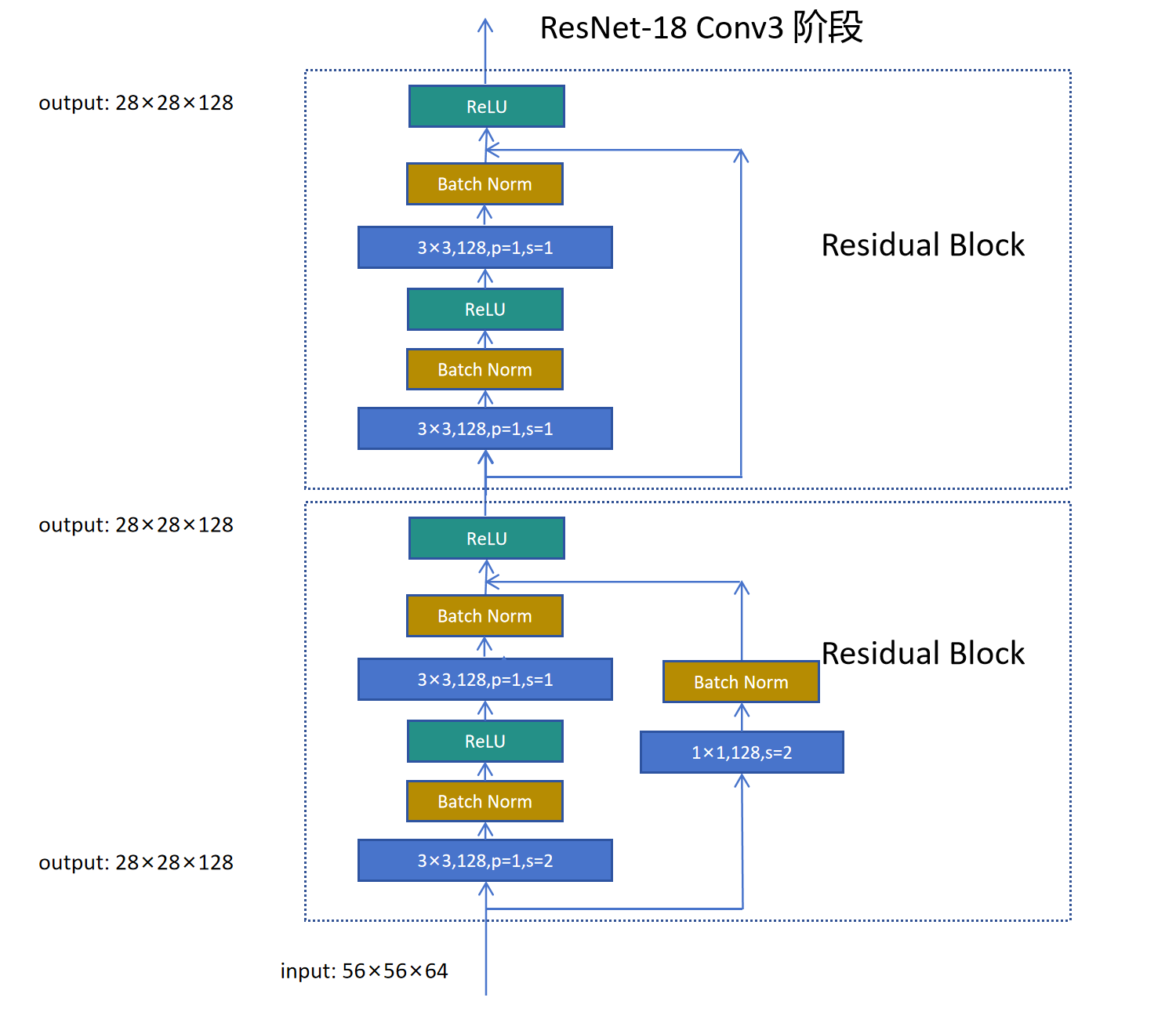
ResNet
ResNet(残差神经网络)由何恺明等人于2015年提出,是深度学习领域里程碑式的工作。ResNet在2015年ILSVRC中以3.57%的top-5错误率夺冠,首次显著超越人类水平(5.1%)。其核心创新是残差学习,使得网络可以训练到极深的层次。在ResNet出现之前,一般的卷积神经网络只能达到30层,而有了ResNet之后,网络深度可以达到100多层,甚至1000层。