Attention
Attention
Scaled Dot-Product Attention (SDPA)
相似度计算 ():计算每个 Query 与所有 Key 的点积,得到一张相似度评分表。
加权求和 ():根据权重提取 Value 中的信息,生成最终的上下文表示。
Softmax 归一化:将评分转化为概率分布,决定模型对每个 Token 的“关注权重”。
Scaled 缩放: 是向量维度:为了解决梯度消失问题,当维度 很大时,点积结果的方差会变大,导致 Softmax 进入梯度极小的饱和区。缩放能让梯度传播更稳定。
Transformer =512
GPT-1 dk=768
GPT-3 dk=12288
LLaMA-3 dk=16k
重点:真正有价值的是V,最后的输出是V中每个元素的加权求和
自注意力机制
目标:信息聚合
自注意力机制引入可训练参数,给QKV矩阵分布做不同的线性变换
目的:帮你更好的去获取重点
每个transformer块里的Attention的三个线性变换里有1.5亿*3个参数
每个block等于一次信息聚合
GPT3是96个block
最后一层的最后一个token是最后的结果
LLaMA3是126层
- 2017年的Transformer:6层,512
- 2018年的GPT:12层,765
- 2019年的GPT-2:48层,1600
- 2020年的GPT-3:96层,12288
- 2023年的GPT-4:120层
- 2024年的Lama3:126层,16384
模型变大:层数变多,向量变长
层多的时候,向量长度也需要相应变长
MHA (Multi-Head Attention)
有没有可能引入多组Wq、Wk、Wv,同时进行多组Self Attention的聚合计算,最后再整合
特征提取
12288->128,需要分96个头(GPT3这么分的)
每层最后结果是96个头的结果
- 首位相接拼接起来,
- 输入进入神经网络W_o进行融合
想尽一切办法理解相关信息
Masked/Causal Attention
计算注意力的时候只计算自己和自己之前的,不能看之后的
Decoder-only 架构
- Masked Attention
- FFN
Embedding 6亿参数
GPT3 的1750亿参数
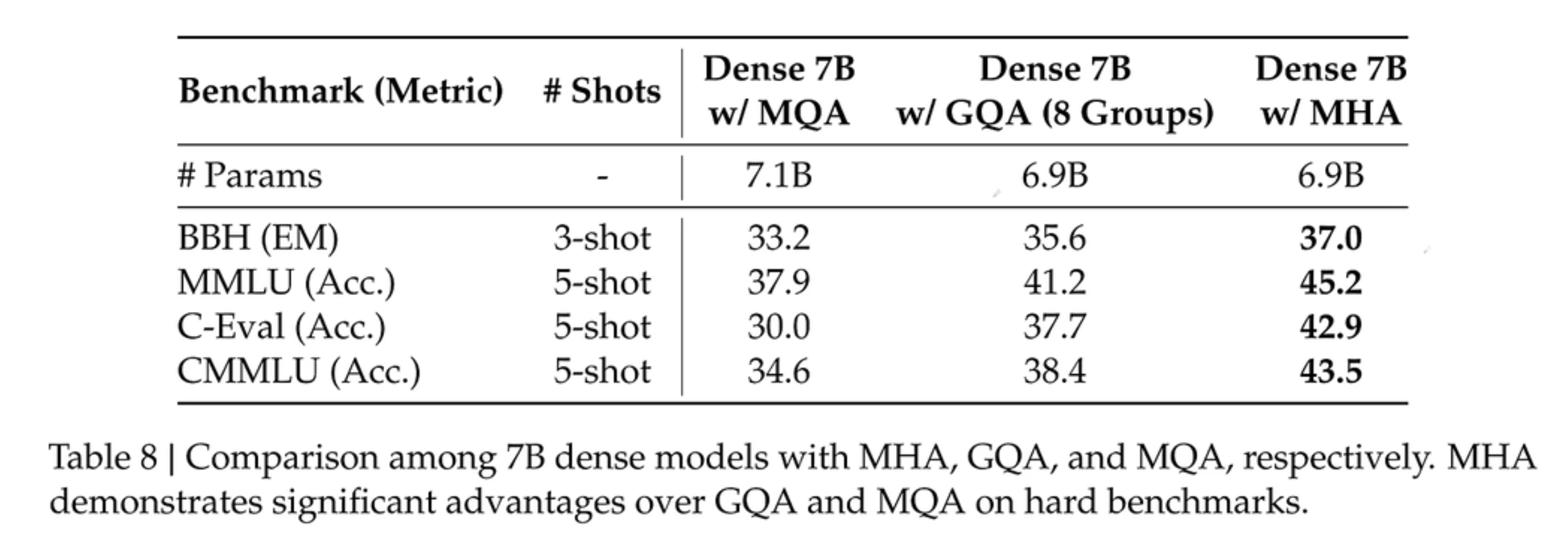
Grouped-Query Attention
MQA (Multi-Query Attention): 所有头共享一个KV (和单头注意力差不多了)
GQA (Grouped-Query Attention): 几个头一组共享一个KV

MLA (Multi-head Latent Attention)
通过 Low-rank Compression (低秩压缩) 将 K 和 V 压缩成一个短的 Latent Vector。在推理时通过矩阵吸收(Absorption)直接计算,不仅显存占用比 GQA 还要低,且性能甚至超越了原始 MHA。
合并矩阵,可以提前融合矩阵,规避解压隐特征带来的额外计算
WVK和W融合
WUv和W°融合
: 压缩Q
: 压缩KV
DSA (DeepSeek Sparse Attention)
对 DeepSeek 之前引以为傲的 MLA (Multi-head Latent Attention) 的一次“稀疏化升级”。
在 V3.1 之前,DeepSeek 依靠 MLA 压缩 KV Cache;而 V3.2 通过 DSA,让模型在计算注意力时,不再盲目地“看”所有 Token,而是通过一个**“闪电索引器(Lightning Indexer)”**,只挑选最相关的部分进行计算。
DSA 的实现逻辑可以概括为:“动态选择 + 局部常驻 + 低秩压缩”。
闪电索引器 (Lightning Indexer)
这是 DSA 的灵魂。它是一个轻量级的门控网络(Routing Network),负责在计算注意力之前做一个“预判”:
工作流:它将输入的 Token 映射到一个低维空间,计算每个 Token 与当前 Query 的相关性得分。
Top-K:它只挑选得分最高的 个 Token 进入全局计算。
技巧:为了保证搜索的效率,DeepSeek 使用了
- Walsh-Hadamard 变换
- 8-bit 量化
来加速索引过程。这使得“找 Token”的过程几乎不占计算耗时。
混合注意力路径 (Hybrid Path)
DSA 并没有完全抛弃全局信息,它将注意力分成了两条并行路径:
- 局部滑动窗口 (Sliding Window):每个 Token 始终能看到其周围一定范围(如 256 或 512 个 Token)内的信息,保证了基础的语法和短程逻辑。
- 动态全局稀疏 (Dynamic Sparse):由索引器挑选出的 个跨度很大的关键 Token,保证了长文档中的跨篇章关联。
C. 与 MLA 的深度融合
DSA 是直接构建在 MLA 基础上的:
- MLA 负责将 KV 压缩成潜在向量(Latent Vector)来省显存。
- DSA 在这个压缩后的向量空间上进行稀疏采样。
- 结果:显存占用不仅因为 MLA 而变小,计算量又因为 DSA 而变轻。
Problem
Attention Sink: 越深的层越会关注第一个token
Attention Sink来源于Transformer需要Context Aware的Identity Layer,即需要Attention Block根据Context不输出任何变化的能力。
Gated Attention Layer
当前的 Transformer 架构中,Attention 层的输出通常直接线性投影。作者提出在 Scaled Dot-Product Attention (SDPA) 的输出之后,直接加入一个 Sigmoid 门控机制。
核心收益:
- 性能提升:在 15B MoE 和 1.7B Dense 模型(训练数据达 3.5T token)上,PPL 和下游任务(MMLU, GSM8k 等)均有显著提升。
- 训练极其稳定:该机制几乎消除了训练过程中的 Loss Spikes,使得模型可以使用更大的学习率进行训练,这对于大规模模型训练至关重要。
- 消除 Attention Sink:这是个意外之喜。该机制引入了 Input-dependent sparsity,使得模型不再需要将注意力强行分配给首个 Token,从而天然地消除了 Attention Sink 现象。
- 长窗口外推能力增强:在进行长 Context 扩展(如使用 YaRN)时,Gated Attention 的表现显著优于 Baseline。