CLIP
5/10/26About 1 min
CLIP
Contrastive Language-Image Pre-training
ITC (Image Text Contrast)
图像分类
Contrastive Language-Image Pre-Training (利用文本的监督信号训练一个迁移能力强的视觉模型)
- 这家伙有什么用呢?想象一个咱们训练图像分类的场景
- 训练1000个类别, 预测就是这1000个类别的概率, 无法拓展
- 新增类别还得重新训练重新标注太麻烦了, 能不能一劳永逸呢
- 这就是CLIP要解决的问题, 预训练模型直接 zero-shot
- CLIP 在完全不使用 ImageNet 中所有数据训练的前提下
- 直接 Zero-shot 得到的结果与 Resnet 在 128W Imagenet数据训练后效果一样
- 传闻使用 4 亿个配对的数据和文本来进行训练, 不标注直接爬取的
- 现在CLIP下游任务已经很多了, GAN, 检测, 分割, 检索等都能玩了
图片编码器
- ResNet
- ViT
训练模型:
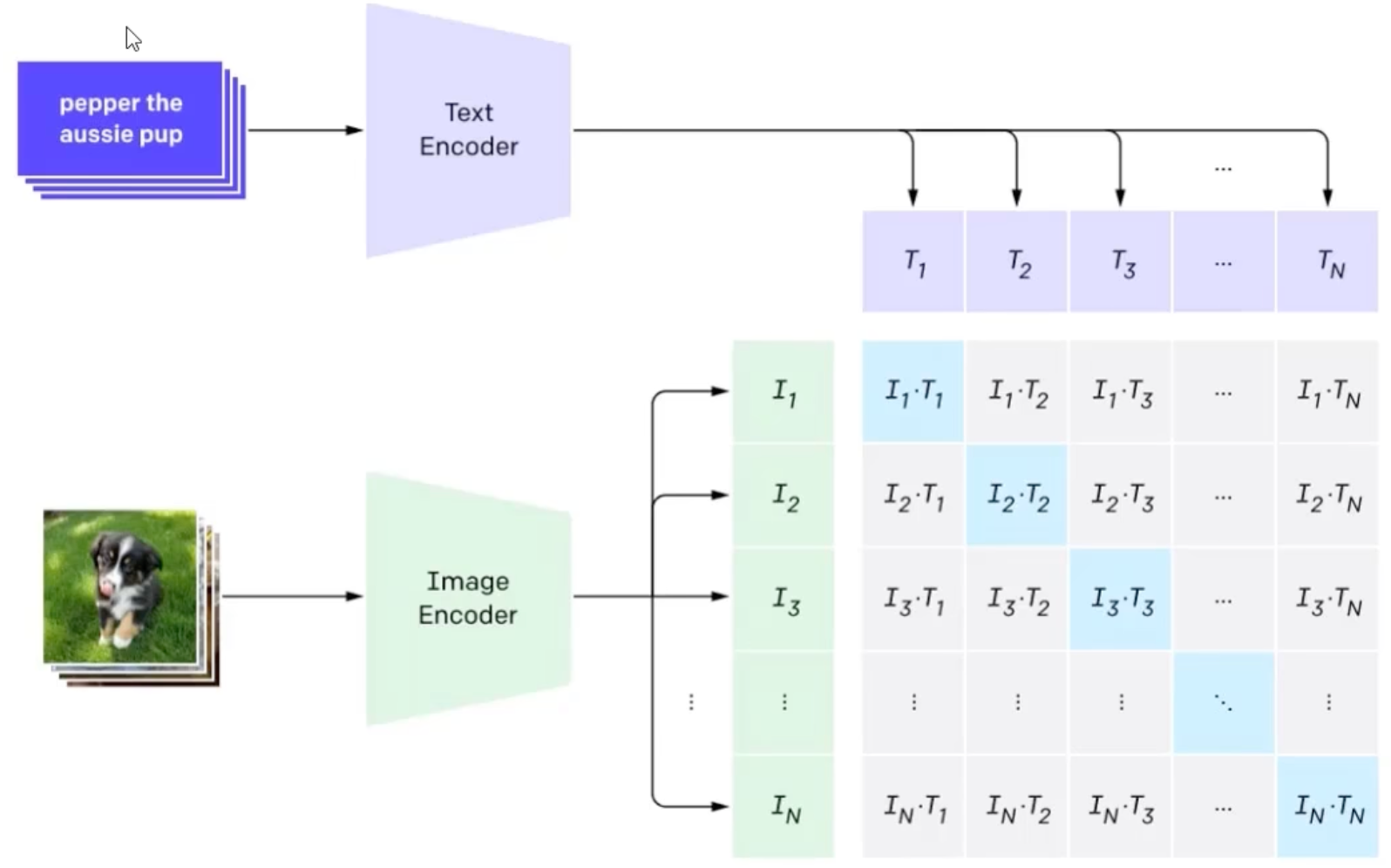
预训练:正样本拉近,负样本拉远
Lecun 世界模型
图形 Encoder
# image_encode - ResNet or Vislon Transformer
# text_encoder - CBON or Text Transforme
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned text
# W_i[d_i, d_e] - learned proj of image to enbed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extrac feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimoda embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# synmetric 1oss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2InfoNCE (Information Noise-Contrastive Estimation)
拓展
ImageBind
SigLIP
四亿图文对
ITC 架构:图像文本对比学习架构