Vision Transformer
5/10/26About 1 min
Vision Transformer
- Transformer模型可以不做改动来解决计算机视觉问题。
- 小规模数据上略输卷积神经网络;中等或者大规模数据集上,表现相当于或者优于卷积神经网络。
- 在计算效率上,训练同等精度的模型,Transformer模型比卷积神经网络模型更有优势。
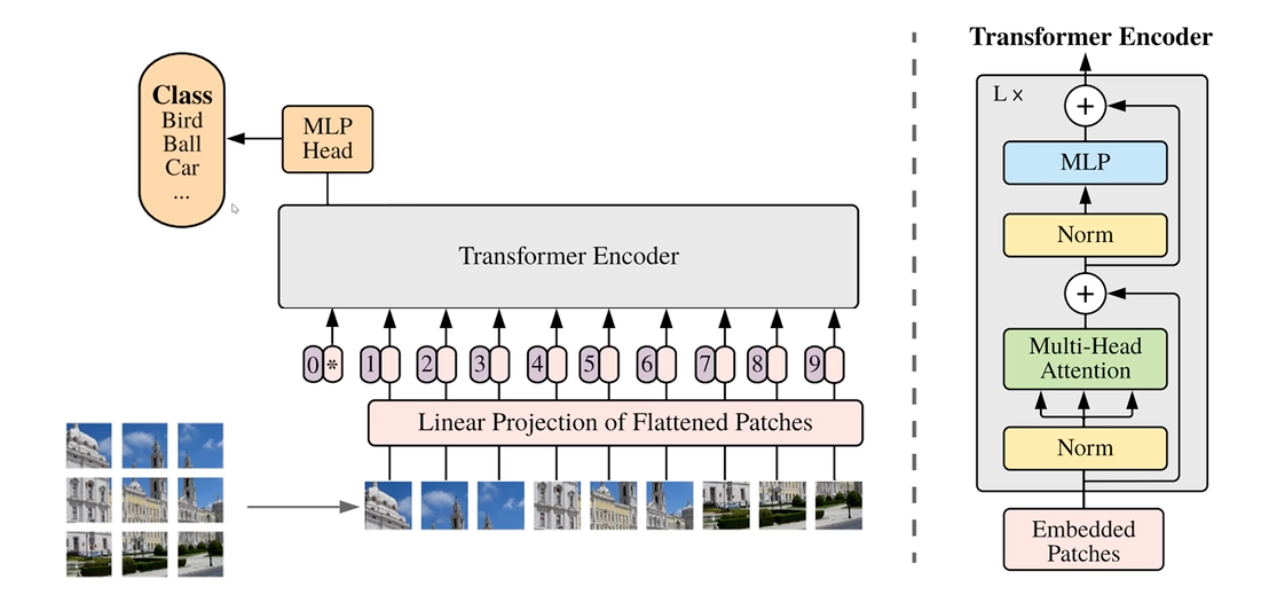
- 一个 patch 为 16
- 位置编码
模型种类
| Model | Layers | Hidden size D | MLP size | Heads | Params |
|---|---|---|---|---|---|
| ViT-Base | 12 | 768 | 3072 | 12 | 86M |
| ViT-Large | 24 | 1024 | 4096 | 16 | 307M |
| ViT-Huge | 32 | 1280 | 5120 | 16 | 632M |
Table 1: Details of Vision Transformer model variants.
ViT-L/16: ViT-Large with 16 * 16 patch size
patch size越小, 序列越长, 计算代价越大。
映射
图像转化为 Embedding 序列两种实现方式
训练图片大小为224224, patch大小为1616, patch数量为14*14。
Transformer里的特征维度 (Hidden_Size) 为1024.
线性映射:
将原始图片拆分为多个patch, 对于每个patch, shape为 (16,16, 3) , 展开为一个长度为768的一维向量, 然后通过一个共享的 (768, 1024) 的线性层进行编码。
卷积操作:
直接对原始图片, 定义1024个卷积核, 每个卷积核大小为patch大小 (16,16) , 步长也为16, padding为valid。
这两个操作是完全等价的。
位置编码
NaViT
Native Resolution ViT