Qwen VL
5/10/26About 1 min
Qwen VL
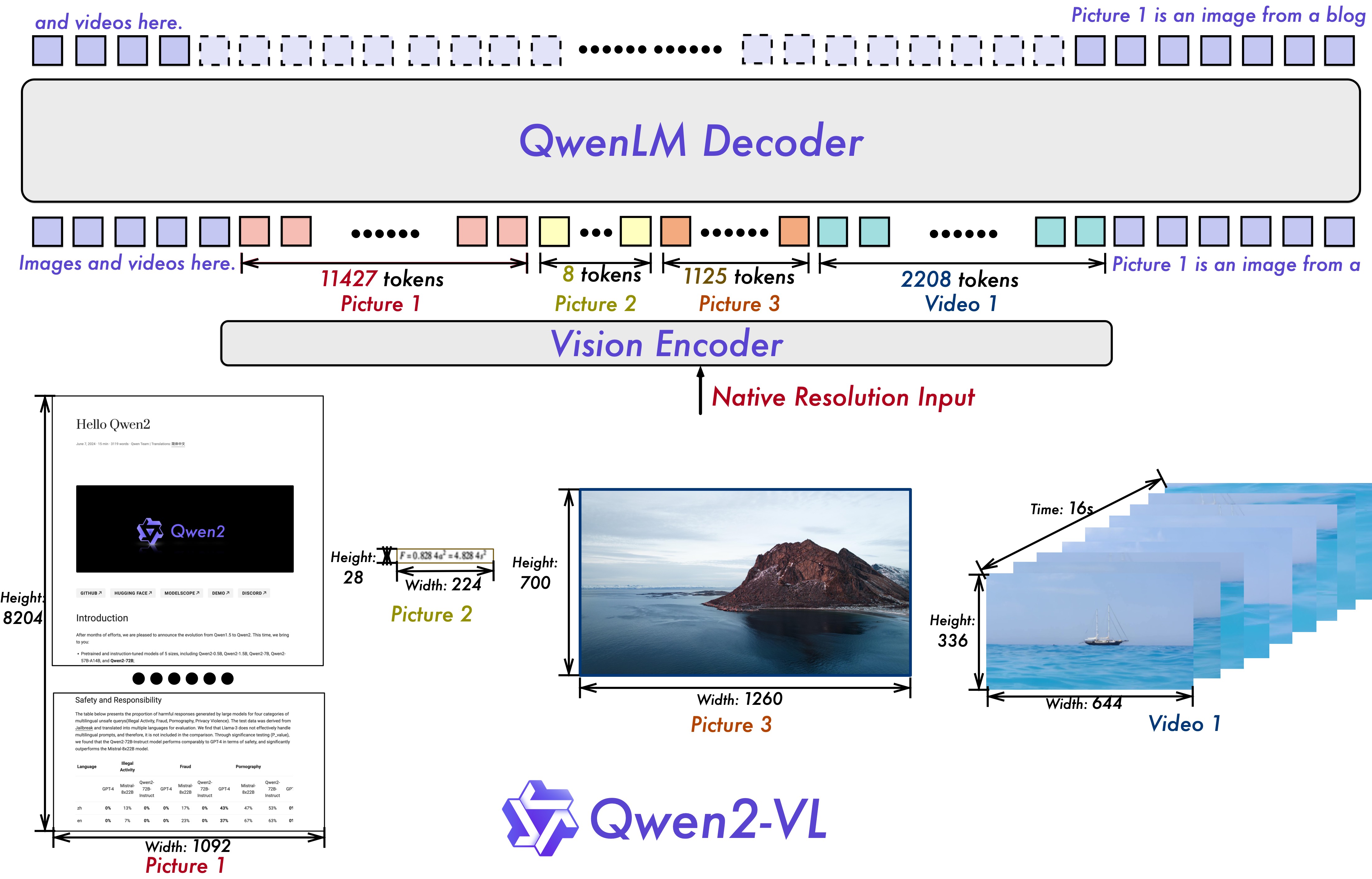
整体上我们仍然延续了 Qwen-VL 中 ViT 加 Qwen2 的串联结构,在三个不同尺度的模型上,我们都采用 600M 规模大小的 ViT,并且支持图像和视频统一输入。为了让模型更清楚地感知视觉信息和理解视频,我们还进行了以下升级:
Qwen2-VL 在架构上的一大改进是实现了对原生动态分辨率的全面支持。与上一代模型相比,Qwen2-VL 能够处理任意分辨率的图像输入,不同大小图片被转换为动态数量的 tokens,最小只占 4 个 tokens。这种设计不仅确保了模型输入与图像原始信息之间的高度一致性,更是模拟了人类视觉感知的自然方式,赋予模型处理任意尺寸图像的强大能力,使其在图像处理领域展现出更加灵活和高效的表现。
| 特性 | Qwen-VL | Qwen2-VL | LLaVA-Next (1.6) |
|---|---|---|---|
| 视觉基座 | ViT-bigG (OpenCLIP) | SigLIP (类似于 BLIP-3) | CLIP-ViT-L |
| 连接器 | C-Abstractor (Resampler) | C-Abstractor (2层 MLP + Pooling) | 2层 MLP |
| 视觉Token数 | 固定 256 | 动态 (Dynamic) | 动态 (随切片数量变化) |
| 分辨率策略 | 固定 448x448 (需缩放) | NaViT (原生分辨率,无填充) | AnyRes (物理切图+拼接) |
| 位置编码 | 绝对位置编码 | M-RoPE (3D 旋转编码) | 标准 RoPE |
| 优势场景 | 物体定位 (Grounding) | OCR、长图、长视频 | 通用对话、单图理解 |